ターゲティング広告を取り巻く環境は、現在大きな変化が起きています。
その背景として、AppleやGoogleといった大手ハイテク企業がサードパーティ・クッキーのサポートを段階的に廃止しており、オープンなインターネット上でデジタル・アイデンティティを追跡する従来の方法は時代遅れになりつつあります。
また、インターネットの47%が、クッキーやデバイスIDの廃止によりアドレス指定できなくなっており、2024年末にはGoogle Chromeからクッキーが廃止されると、その割合は90%以上に上昇します。
広告主にとって、これはデジタル・アイデンティティを構築するための頼みの綱であったデータ・シグナルが消えつつあることを意味します。
広告業界だけではなく、ターゲティング広告を実施している企業にとっても、このシグナルの喪失が意味するものは非常に大きいのです。
では、企業はどのように適応していけば良いのでしょうか?
先日、Aerospikeのアドテック担当グローバル・ディレクターDaniel Landsmanと、プロダクト・マネジメント・ディレクターのIshaan Biswasとの対談で、シグナルロスの意味と、それに対処するためのテクノロジー・ソリューションを探りました。
決定論的モデルと確率論的モデル

「広告主はROAS(広告費用対効果)に注目しています。これは、広告に費やした予算がどのようにしてトップラインの成長に役立っているかを理解するために使用される指標です。」
とLandsmanはいいます。
「問題は、クッキーなしでその指標をどのように作成するかです。」
クッキーを使用することで、ターゲティング広告を行う企業は顧客のジャーニーを決定論的に追跡する方法を持っていました。
それらがない場合、彼らは確率論的モデルを活用して、ユーザーフローを通じたカスタマージャーニーを理解し、彼らが広告クリエイティブとどのように相互作用しているかを見ることを目指しています。
「要するに、AdTech企業にとって、ユーザーを識別するために使用されていた予測可能なシグナルであるクッキーは、なくなっているか急速に減少しています」
とBiswasは言います。
「したがって、彼らは同じタスクを達成するために確率論的モデルを採用しなければなりません。」
効果を出している企業は、カスタマージャーニーを包括的に見ることができ、あらゆる場所からシグナルを引き出すことができます。
「企業は、「レイヤーケーキアプローチ」を取る必要があります」
とLandsmanはいいます。
「第一者データ、第二者データ、第三者データに傾倒し、シグナルの損失が続く中で、どこからでもそれを得ることです。」
これは、アトリビューションにおいて買い手側でも同様です。
「人々は最後のクリックアトリビューションを使用し、マルチタッチアトリビューションで作業してきました。しかし、シグナルの損失により、それがますます困難になっています。」
この課題に対応するために、多くの企業はアイデンティティグラフに目を向けています。
アイデンティティグラフとは、個々の消費者のアイデンティティ(身元)に関連するデータポイントを統合し、相互に関連付けるためのデータモデルです。
アイデンティティグラフの役割は、包括的な顧客ビューを提供することです。
消費者のさまざまな属性や行動、デバイスの使用、オンラインとオフラインの活動など、多様な情報源からのデータを結びつけることにより、より完全で包括的な顧客プロファイルを作成します。
彼らは、さまざまなタッチポイント、デバイス、チャネルからの顧客データを一つの統合されたプロファイルにまとめます。
この360度ビューにより、マーケターは顧客の行動を包括的に理解し、よりパーソナライズされた効果的なキャンペーンを作成するのに役立ちます。
彼らは、この豊かな顧客ビューとターゲットオーディエンスを使用して、よりパーソナライズされたコンテンツ、レコメンデーション、およびオファーを提供し、消費者全体のエンゲージメントを高め、コンバージョン率を向上させることができるのです。
クッキー情報が利用できなくなった今、顧客を識別するための情報が必要です。
そして、その一助となるのがアイデンティグラフなのです。
グラフデータベースを考える

シグナルが多様化し確率論的アプローチが不可欠になるにつれて、アドテック開発者は今後最も意味のあるデータモデルの種類を見直すようになっています。
そして彼らの多くが、顧客/ユーザーとそのジャーニーの両方を表現するグラフデータベースに注目しています。
グラフデータベースとは

グラフデータベースは、データをデータ・ポイント(ノード)と、これらのノードをつなぐ関係(エッジ)の集まりとして表現します。
グラフデータベースは、例えば、人々、彼らのデバイス、彼らの興味、彼らの組織などの間の関係を、自然で理解しやすい形で表現します。
そして、データ構造とスキーマの面で非常に柔軟性があります。
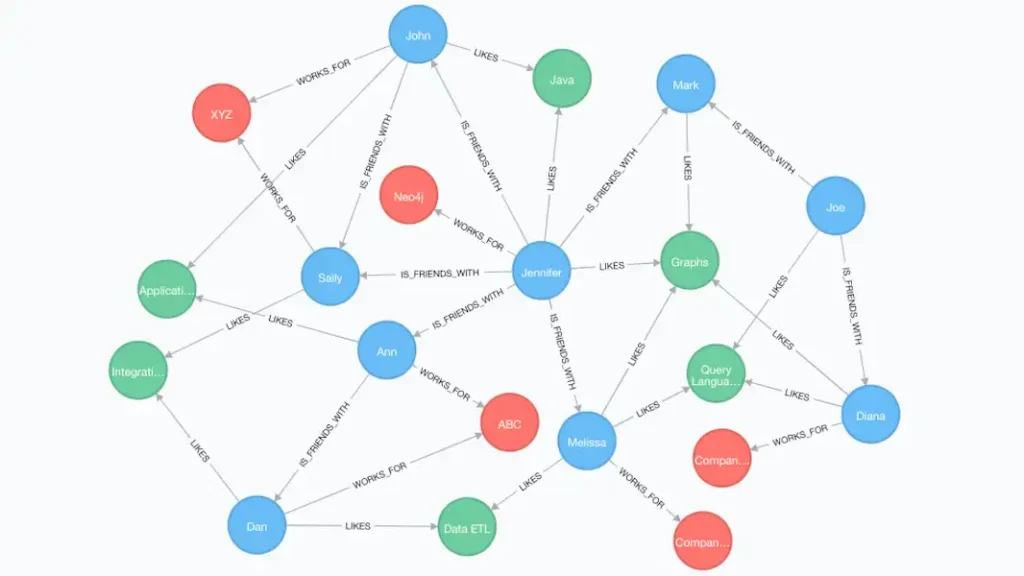
図1:グラフ・データ・モデルは、確率的アイデンティティ・モデルの複雑さを簡単に処理できる
グラフデータベースでできること
グラフデータベースを使うことにより、顧客の行動やジャーニーを簡単にモデル化し、広告費を最適化し、さらにはパーソナライズされた広告を提供することができます。
また、様々なタッチポイントやトリガーから統合された個人やグループの様々なビューを可能にします。
これには、位置情報、デモグラフィック、購買パターン、ノードではなくエッジとして表現した方が良いその他の行動が含まれます。
一例として、クッキーのような決定論的シグナルがない場合でも、グラフデータベースを使えばクロスデバイス追跡を行うことができます。
グラフデータベースは、広告主がターゲティング、アトリビューション、そしてカスタマー360のようなその他の重要事項を改善するために使用できる、よりリッチで洗練されたアイデンティティの表現を可能にするため、アドテクにおけるアイデンティティの解決に自然にフィットします。
グラフを活用した360度ビューにより、マーケティング担当者は顧客の行動をより包括的に理解し、よりパーソナライズされた効果的なキャンペーンを展開することができます。
「グラフ・データ・モデルは、オープン・インターネットにおけるスケールの大きなオーディエンスへの対応に移行する上で、大きな助けになると信じています。
グラフデータベースの評価基準

グラフデータベースを決めたら、必然的にネイティブグラフ・データベースかマルチモデル・データベースのどちらかを選ぶ必要があります。
どちらも適しており、それぞれに利点があります。
どちらを選択するにしても、アイデンティティ・グラフの目標を達成するために満たさなければならない基本的な基準がいくつかあります。
データのモデル化
グラフデータベースを決定する最も説得力のある理由の1つは、そのモデルがいかに表現的で直感的であるかです。
したがって、データをネイティブなグラフ形式でモデル化し、保存するのに役立つグラフデータベースが重要です。
問題は、ユーザ、デバイス、クッキーをどのように頂点と辺としてモデル化するかということです。
「プロパティグラフモデルはそれが得意です。」
とBiswasはいいます。
「つまり、市場に出回っているほとんどのグラフ・データベースがこれを実現できるのです。これは確立された技術なのです。」
ネイティブなクエリ言語
グラフデータベースは、グラフネイティブのクエリーとトラバーサルをサポートする必要があります。
いくつかあるが、GremlinとCypherが最も一般的で、グラフデータのクエリーとトラバースに役立ちます。
グラフクエリ言語は、グラフの関係やトラバースを簡単に表現し、効率的にデータを取得することができます。
パフォーマンスとスケール
AdTechやMarTechシステムは、ユーザープロファイルストア、マルチタッチアトリビューション、広告オークションなど、アイデンティティ解決を行う場合、数百万から数兆のデータを扱います。
そして、それは数十億の頂点とそれぞれ数千のエッジに変換されます。
そのため、特殊なグラフデータベースが必要になるのです。
特に広告業界においては避けられないスケールの問題です。
人々は、膨大な量のデータを処理し、ミリ秒単位でアクセスでき、予測可能な待ち時間で処理できるグラフデータベース技術に注目し始めています。
水平スケール(クラスタ化されたデータベースにノードを追加すること)は、低レイテンシーを維持しながら、データ量とクエリスループットの両方でデータ量の増加に対応します。
つまり、1桁または2桁前半のミリ秒です。
さぁはじめよう!5段階のプロセス

アイデンティティ・グラフのジャーニーを始めるにあたり、グラフ・データベースを使用したスムーズな移行を保証するために、5つのプロセスをご紹介します。
1. ビジネス・プロセス/問題文の定義
まず、実現したいビジネスプロセスを定義します。
Customer 360のプロセスを微調整するにしても、広告オークションをパワーアップさせるアイデンティティ・グラフを作成するにしても、それらのビジネス・プロセスについて規定する必要があります。
これには、組織内の技術関係者とビジネス関係者が協力して行う必要があります。
機能基準とパフォーマンス基準の成功指標を定義してください。
2. データを知り、スキーマを作成する
データを照会するには、ID グラフのデータ構成、言い換えればスキーマを定義する必要があります。
そのためには、まず以下について確認してください。
- 達成しようとしている最終目標は何か?
- 実装したいビジネス・プロセスは何か。
どのようなデータを持っているのか、あるいはアクセスする必要があるのか? - 協力しているデータ・ブローカーは誰か?
これらの質問に答えられれば、スキーマを定義することができます。
組織によって、アクセスできるデータによって、スキーマは異なりますし、また時間とともに進化していきます。
3. クエリーを書き出す
グラフ・データ・モデルの直感的な性質により、グラフ・クエリを平易な言葉で構築することができます。
そのため、クエリの想像を膨らませるために、やりたいことを平易な言葉で書き出してみましょう。
基礎となるグラフ・クエリ言語については気にしなくても大丈夫です。
あなたのクエリは理にかなっていますか?
4. サンプルデータと Gremlin クエリの作成
サンプルデータセットを作成し、データベースにデータをロードします。
その後、データベースへのクエリを開始します。
ステップ1で書き出した記述に基づいてクエリを作成し、データベースに問い合わせます。
うまくいかなかった場合は、何度か繰り返してみてください。
5. スケール、テスト、最適化
構築したものに満足したら、規模を拡大し、成功指標を達成するまで反復します。
グラフ・データベースを選択したら、手持ちのデータをすべて取り込み、クエリーをアプリケーションに組み込み、規模を拡大し、世に送り出します。
これらのステップにはそれぞれ微妙な違いがあるのは明らかだが、一般的なプロセスとしては問題ありません。
希望するパフォーマンス目標を達成するまで、データモデリング、クエリ、スキーマ、データベースのスケーリングを何度か繰り返す必要があります。
アイデンティティグラフの次のステップ
Aerospikeは、Paypal、Adobe、Signal(現TransUnion)、Aqferで導入されたソリューションを通じて、アイデンティティグラフに関する専門知識を持っています。
詳しくはこちらからお気軽にお問い合わせください。
このブログは、2023年11月10日のブログ「Graph databases and signal loss in AdTech」の翻訳です。