人工知能(AI)の価値は、リアルタイムで動作できるようになると著しく向上し、より速く、より影響力のある意志決定と行動を可能にします。
しかし、大規模言語モデル(LLM)がリアルタイムであることは、彼らが要求する計算負荷とそれに伴うコストのために困難です。
良いニュースは、レイテンシー、コスト、リアルタイムアクセスが相互に関連しており、レイテンシーを削減する方法を見つけることで、コストも削減され、リアルタイムアクセスの実現も容易になるということです。
このように語るのは、カリフォルニア州メンロパークにあるLamini社の共同創業者兼CEOであるSharon Zhou博士です。
同社は企業向けに統合されたLLMファインチューニングと推論エンジンを構築しています。
以前は、彼女はスタンフォード大学のコンピューターサイエンス学部で生成AI(GenAI)の研究グループを率いていました。
また、Andrew Ng博士の下でGenAIの博士号を取得しました。
彼女は、Real-Time Data Summitで、AIの力を活用してレイテンシー、コスト、リアルタイムアクセスのジレンマに対処するというテーマで講演しました。
リアルタイムの主な課題
Zhouは、AIドリブンのアプリケーションをリアルタイムで提供することを困難にする3つの主な領域を挙げています。

計算
AIアプリケーション、特にLLMが膨大な計算を必要とすることは周知の事実です。
そして、単一のクエリに対してさえ、数十億単位の計算が必要です。
これは過去の機械学習(ML)から大きな変化です。
Zhouは、数年前でさえ、100万のパラメータでも巨大で考えられないほどだったと言います。
一見単純な例を挙げてみましょう。
「『こんにちは、調子はどうですか?』とLLMに尋ねただけでも、『こんにちは』という単語に対して、次に『調子』、そして『どう』に対して全ての計算を行っています」。
そして、これら全てを処理するのは非常にコストがかかります。
しかし、これは始まりに過ぎません。
LLMは入力を解釈するだけでなく、出力を作成する必要があり、それも同様に複雑です。
例えば、『こんにちは、調子はどう?元気です』という場合、読み取りや書き込むのにも時間がかかります。
そして、モデルが大きくなればなるほど、計算量も増えます。
GPT-3やChatGPTのようなモデルである1000億パラメータモデルの場合、それは非常にコストがかかります。
実際のアプリケーションで、単に「こんにちは、調子はどう」と言うだけでなく、LLMに追加データを与える場合を想像してみてください。
例えば、ユーザーのサインインが不正かどうかを検出したい場合、多くの異なるユーザーデータをモデルに渡すことになります。モデルはそれら全てを読み取り、答えを出さなければなりません。
実際のアプリケーションではより複雑な出力も必要です。
「モデルが言ったことの理由、それがYesであれNoであれ、説明を求めることになります」とZhouは説明します。
コスト
リアルタイムLLMを非常に高価にする主な要因が3つあります。
1つは、モデルを1回実行するだけでもコストがかかること。
ウェブサイトにpingを送るよりも確実に高価です。
1回の実行は1セントの一部程度のコストかもしれませんが、モデルにより多くのデータを与えると、それが積み重なっていきます。
さらに、計算負荷が非常に重いため、それを処理するために完全に新しい信頼性の高いインフラストラクチャを構築する必要があります。
Zhouは「これは非常に難しく、非常に複雑なソフトウェアエンジニアリングの問題です。」と言います。
加えて、システムを維持する必要があります。
「この分野は非常に速く動いています」と彼女は言います。
新しいモデルや新しいタイプのアーキテクチャが常に登場している中、それにどうやって追いつくのでしょうか?
スケーリング
小規模な概念実証から本番アプリへのスケーリングは、リアルタイムAIの3番目の課題です。
実際のアプリケーションでは、おそらくモデルを1回呼び出すのではなく、多数回呼び出すことになります。つまり、複数のモデルを呼び出しています。
そして時には30個もの数に及ぶと彼女は言います 。
そのレイテンシーは積み重なります。
それぞれのモデル呼び出しは秒単位の時間がかかり、30秒であれ1秒であれ、それが積み重なって30秒や900秒になります。
そのため、これらのアプリケーションをスケールすることは非常に困難です。
低レイテンシーアプリを開発するための3つのヒント
Zhouは、AIアプリケーションパイプラインでレイテンシー改善を目指すべき領域として、AIモデル、データがモデルに到達する前後のステップ、そしてアプリ自体を特定しています。
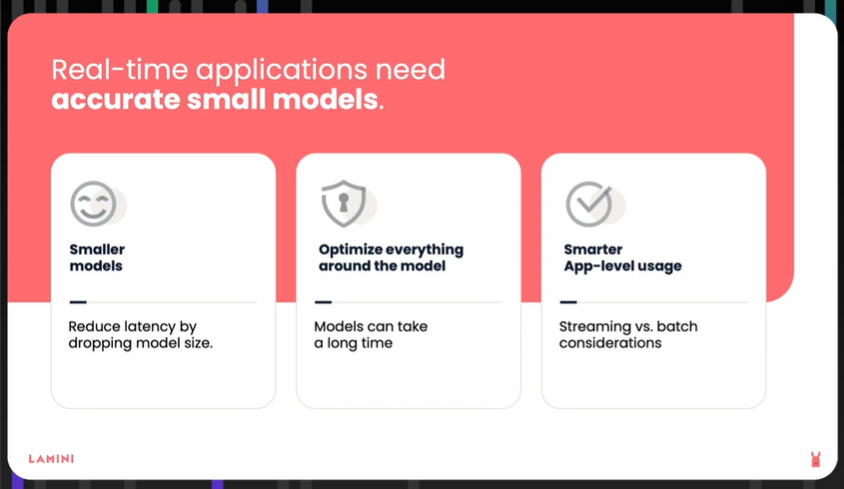
小さなモデルから始める
小さなモデルは計算量が少なくなります。
使用可能な最小の脳を考え、そこから始めることができます。
これにより、応答時間が秒単位ではなくミリ秒単位になると彼女は説明します。
全体のパイプラインを最適化してレイテンシーを増加させる可能性のある操作を減らす
モデルに多くの読み取り、出力、書き込みをさせる様々な要素を考え抜いてください。
アプリケーションレベルで考える:
本当にそれら30のモデル全てが必要なのでしょうか?
「これらのモデルをより賢く使用する方法を考え抜いてください」とZhouは言います。
「このリアルタイムアプリケーションを計画する際に、これを前もって考えてください。」
リアルタイムアプリケーションが必要とするレイテンシーを正確に知ることで、「どこから始め、どのサイズのモデルから始め、どこをリアルタイムにする必要があるかを考える方法がわかります」と彼女は言います。
また、重要なのは単一のトークンのレイテンシーだけでなく、ユーザーへの全体の応答のレイテンシーだとZhouは言います。
多くの場合、我々が気にしているのはレイテンシーだけでなく、そのレイテンシーのスケーラビリティ、バッチレイテンシー、入ってくる異なるリクエストのスループットです。
役立つのは、アプリが一度に複数のリクエストを処理する方法を探すことです。
「これはスループットにとって本当に重要で、直列的に処理しないようにします」と彼女は言います。
複数のリクエストを受け取り、それらが同時に来なくてもバッチ処理することで、バッチレイテンシーを下げることができます。
効率的なアプリ:速さと安さが手を取り合う時
通常、低レイテンシーを実現するにはより高コストになりますが、前述の3つのヒントはそれぞれより効率的なアプローチを提供します。
実際にレイテンシーとコストを一致させ、「互いに直接比例する」ようにするとZhouは言います。
モデルが小さいほど、実行コストが安くなり、必要な計算が少なくなり、したがって、より速く応答できるようになります。
彼女は、OpenAIのGPT-4やGoogleのGemini 1.5などの基盤モデルを例として挙げます。
モデルを改善するときはいつでも、通常レイテンシーを下げながらコストも下げています。
「これらの企業は、人々がまだ使用できる小さなモデルを使用する方法について非常に深く考えています。
そうすることで、ユーザーのコストを下げ、各ユーザーにより速く応答し、したがって二重に良い効果を得て、より多くのユーザーリクエストを処理できるようになります。
リアルタイムAIの成功のための実践的考慮事項
Zhouは、リアルタイムAIアプリケーションのパフォーマンスと効率を大幅に向上させる具体的な技術をいくつか提案しています。
これらには、メモリ管理、モデル品質の最適化、革新的なモデルアーキテクチャの活用などの戦略が含まれます。
メモリ効率
大規模言語モデルの主な課題の1つは、計算能力とメモリの需要です。
Zhouが説明するように、「モデルは計算的に非常にコストがかかり、重いです。また、コンピュータ内部に保存するのに大きいため、多くのメモリを占有します。」
これに対処するため、Zhouはアダプターの概念を紹介しています。
結果、開発者はモデルの一部分だけを調整でき、モデルをかなり小さくし、素早く効率的なモデル交換を可能にします。
このアプローチにより、異なるモデル間の切り替えに必要な時間を数ヶ月からミリ秒に短縮できます。
専門家の混合
Zhouはまた、GPT-4で使用されている「専門家の混合」と呼ばれる技術を用いて、開発者がより大きなモデルのパラメータの一部だけを活性化することで最適化できる方法についても議論しています。
この方法は、特定のタスクをモデルの最も関連性の高い部分にルーティングし、より速い処理を可能にします。
それらの専門家の1つは、モデル全体の8分の1程度の一部分に過ぎません。
カジュアルなチャットで応答するという考えに基本的に無関係なものも含めて、すべての異なるパラメータを通過するよりもはるかに速いです。
モデル品質とチューニング
モデル品質の向上も重要な要因です。
小さなモデルは速い可能性がありますが、特定のユースケースに対する精度を向上させるためにファインチューニングすることもできます。
Zhouは次のように述べています。「ファインチューニングして品質を向上させ、特定のユースケースに対する精度を上げることができます…そして実際に、不正を検出したいのであればそれを行うことができます。」
Lamini Memory Tuning:
Zhouは、彼女の会社Laminiが「Lamini Memory Tuning」と呼ぶ技術について共有して締めくくっています。
Lamini Memory Tuningは、LLMの目的を調整することで、非常に事実に基づいたシステムに変換する技術です。
このアプローチにより、精度が劇的に向上し、実世界での結果が数日で50%から95%にパフォーマンスを引き上げました。
「これらのLLMを非常に事実に基づいたものにすることで、その目的を変更します」とZhouは説明し、Laminiのイノベーションがより効率的で信頼性の高いAIアプリケーションへの道を切り開いていることを示しています。
Aerospike:リアルタイムAIアプリケーションを支えるデータベース
Aerospikeは長年にわたり、そのデータベースでAIアプリケーションを支える最前線にいます。
Zhouと同様に、我々もLLMやその他の類似性駆動型AIユースケースの膨大な可能性と急速な採用を認識しています。
Aerospike Vector Searchは、まさにZhouが提示する課題「スケールでのベクトル検索を低レイテンシーと総所有コスト(TCO)で、すべてリアルタイムで提供すること」に対処するために開発されました。
効率的でスケーラブルなAIソリューションへの需要が高まる中、Aerospikeは引き続き、企業がこれらの目標を確信を持って達成できるようにサポートしています。
このブログは、2024年8月20日のブログ「The challenge of real-time AI: How to drive down latency and cost」の翻訳です。