生成AIの急速な普及により、企業のデータ環境は劇的に変化しています。
ChatGPTやその他の大規模言語モデル(LLM)の台頭によって、
データの量だけでなく、その検索方法や活用戦略も根本から見直す必要が生じています。
特に注目を集めているのが、「意味」で情報を探すベクトル検索技術と、
それを実現するための基盤となるベクトルデータベースです。
この技術は、従来のキーワードマッチングから一歩進んだ、コンテキストや
意味を理解した検索を可能にしました。
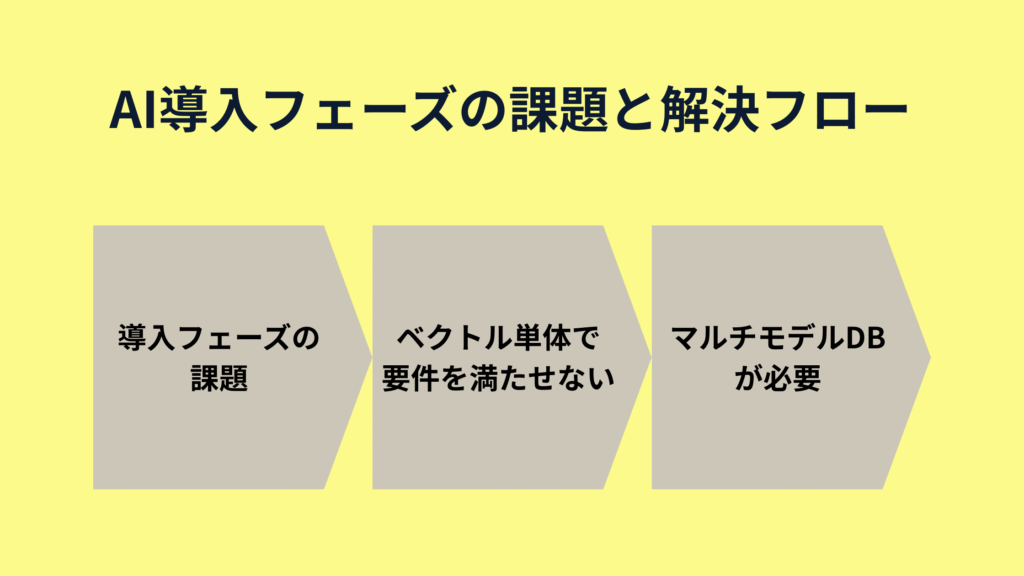
しかし、多くの企業がAI導入のPoC(概念実証)段階を終え、
実運用フェーズに進もうとした際に、共通の課題に直面しています:
- ベクトル検索は革新的だけど、それだけでは業務要件を完全に満たせない
- 顧客同士の関係性やデータ間のつながりも分析したい
- データ構造が頻繁に変わるため、柔軟なスキーマ管理が必要
- 高速なトランザクション処理と意味検索の両立が求められる
このような課題が生じる根本的な理由は、
現代のデータ活用において、単一のデータベースモデルでは限界がある
という事実にあります。
そこで、本記事では、注目を集めるベクトルデータベースと、
複数のデータモデルを統合できるマルチモデルデータベースを徹底比較し、
企業が直面する課題とその解決策を解説します。
また、Aerospikeが提供するマルチモデルデータベースソリューションが、
AIと業務をシームレスにつなぐ方法についても紹介します。
Aerospikeはベクトルデータベースやグラフデータベース、ドキュメント、
キーバリューを統合したマルチデータベースを提供しています。
また、PayPalやAirtel、楽天、Caulisといった世界をリードする企業で
業種問わずご採用いただいています。
「AI活用を加速させたいけど、どのデータベース選びが正解なのか迷っている」
というお悩みをお持ちの方は、こちらからお気軽にご相談ください。
ベクトル検索に注目が集まる理由とは?
従来のデータベース検索は、主にキーワードの完全一致や部分一致に依存していました。
例えば「自動車の維持費」を検索しても、「車のランニングコスト」という
類義語を含む情報は見つからない・・・このような限界がありました。
しかし、生成AIの登場により、この検索パラダイムは大きく変わりつつあります。
ベクトル検索は、文章や画像などの非構造化データを数値ベクトル(埋め込み)に変換し、
意味的な類似性に基づいて検索を行う技術です。
ベクトル検索の仕組みと特徴
こちらは、意味検索を実現する3つのプロセスです。

これにより、キーワードが完全に一致しなくても、
意味的に関連性の高い情報を検索できるようになりました。
ベクトル検索の主な活用事例
- 企業内チャットボット・FAQシステム:社内知識ベースから意味的に関連する回答を提供
- ECサイトの商品レコメンデーション:類似商品を意味レベルで把握し推薦
- 画像検索システム:視覚的特徴の類似性に基づく画像検索
- 顧客サポートの自動化:過去の問い合わせから類似事例を抽出
こうした検索を実現するためには、ベクトルデータの効率的な格納と高速処理が可能な
ベクトルデータベースが不可欠です。
従来のリレーショナルデータベースでは、高次元ベクトルの効率的な近傍探索が困難です。
そのため、ベクトル検索に特化したデータベースが注目されているのです。
それだけでは足りない──グラフやNoSQLも求められる理由
このように、ベクトル検索は、AI時代の情報探索を劇的に進化させました。
しかし、多くの企業がPoCフェーズを終え、実運用に移行する段階で
直面する共通の壁があります。
実際のビジネス要件の複雑性
実際のビジネス要件を考えると、ベクトル検索はあくまでパズルの一部にすぎません。
企業の現場では、以下のような多様なデータ処理ニーズが存在します:
関係性分析の必要性
- FAQ検索には成功したが、顧客同士の関係性を分析できない(→グラフ構造が必要)
- 顧客間のつながりやフローを可視化するにはグラフデータベースが必要
データ構造の柔軟性
- 商品データの形式がバラバラで管理しづらい(→柔軟なスキーマ設計が必要)
- データの形式が頻繁に変わるECサイトではスキーマレスなNoSQLが必要
処理性能の要求
- リアルタイムに大量のリクエストを処理したいが、既存のデータベースではスケールが難しい(→NoSQLのスケーラビリティが求められる)
- IoTや金融のように大量の同時処理が求められる領域では、高スループットな構造も必要
現場で進む「掛け合わせ前提」の発想
こうした背景から、企業の現場では今、
「検索やAI処理はベクトルデータベースで、周辺業務は他モデルで担保したい」
という発想が主流になりつつあります。
これは、単に技術トレンドの話ではなく、本番運用での現実的なニーズです。
- ベクトルデータベースは必要。でも、それだけじゃ業務が回らない
- 業務要件すべてにフィットするデータ基盤がほしい
- 複数モデルを“つなげて”使いたい
そんな企業の声に応えるには、単一モデルのデータベースでは限界があります。
その解決策となるのがマルチモデルデータベース

そこで、今多くの企業が注目しているのが、複数のデータモデルを統合的に扱える
「マルチモデルデータベース」という選択肢です。
マルチモデルデータベースとは、1つのプラットフォーム上でベクトルデータベース、
グラフデータベース、NoSQLのように、複数のデータモデルを同時に扱えるデータベースです。
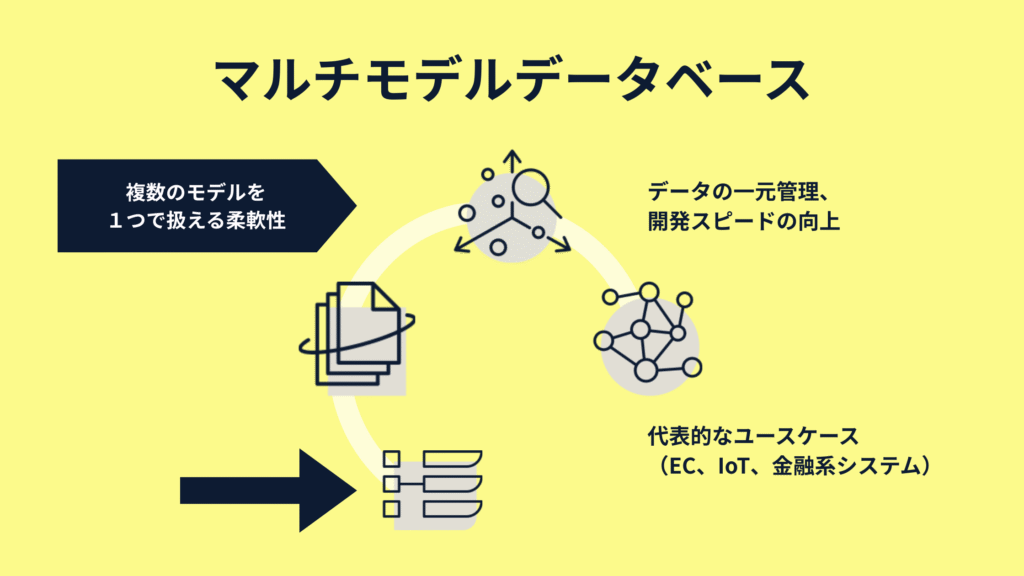
具体的には以下のようなデータモデルを統合的に扱うことが可能です:
- 構造化データ:キー・バリューやリレーショナルデータベース的な処理
- 関係性データ:グラフデータベース的なモデリング
- 柔軟なデータ形式:ドキュメント(JSON)やNoSQL構造
- AI処理:ベクトル検索
これらをひとつの基盤上で共存・連携できるのが、マルチモデルデータベースの最大の強みです。
なぜ今、マルチモデルが選ばれているのか?
1つのプロジェクトに複数のデータモデルを使うのは、今や当たり前になっています。
にもかかわらず、モデルごとに異なるデータベースを導入していては──
- 開発や保守にコストがかかりすぎる
- データが分断され、AI活用の障壁になる
- 拡張や変更があるたびにシステム全体を見直す必要がある
こうした問題を根本的に解決できる構造こそが、マルチモデルデータベースです。
導入メリットは「柔軟性とスピード」
マルチモデルデータベースを導入することで、以下のような効果が期待できます。
- 複数のユースケース(検索・分析・レコメンデーションなど)を1つの基盤でカバー
- スキーマの変更や新しいモデル追加も柔軟に対応
- 開発・運用チームの負荷を軽減し、リリーススピードを高速化
つまり、AI活用のポテンシャルを最大化しながら、現場の業務要件にも寄り添うことができます。
Aerospikeデータベース:マルチモデル×ベクトル検索の統合基盤
「AI活用は進めたい。でも、業務要件とのすり合わせが難しい」
そんな悩みに対して、マルチモデル×ベクトル検索を“ひとつの基盤”で実現できるのが、
Aerospikeデータベースです。
Aerospikeデータベースのコア機能
Aerospike データベースは、以下のような複数のデータモデルをネイティブにサポートしています:
- ベクトル検索:高精度な意味ベースの類似検索(生成AIやレコメンドに最適)
- キー・バリュー/セカンダリインデックス検索:トランザクションや高速ルックアップに強み
- スキーマレスなドキュメント構造:NoSQL的な柔軟性もカバー
- グラフ構造との連携:ネットワーク関係の可視化や分析にも対応
これにより、AI処理と周辺業務処理を1つのデータベースで完結することができます。
マルチモデル×ベクトルデータベースを「リアルタイムで」動かせる強さ
Aerospikeの最大の特徴は、超高速・低レイテンシーでのリアルタイム処理です。
- 1秒あたり数百万件の処理が可能
- SSD・DRAM・PMEMを使った独自のストレージ構造で高速化
- インデックスの自動最適化により、処理が重くならない
AI時代のデータベースに求められる「意味理解」「速度」「柔軟性」を、すべて高次元で実現します。
Aerospike データベースを選ぶ5つの理由
ここで、Aerospike データベースが選ばれる理由を5つの観点で整理します。
1. AI活用に最適化されたアーキテクチャ
ベクトル・グラフ・ドキュメント・キーといった多様なデータを高速かつ統合的に処理可能。
リアルタイムなAIユースケース(検索、レコメンド、判断)に強みを発揮します。
2. スケールアウト可能な高性能
HNSWインデックスを並列かつ分散で構築でき、水平スケーリングにも対応。
大規模データ環境下でも安定したパフォーマンスを維持できます。
3. 低TCO(Total Cost of Ownership)
独自のハイブリッド・メモリアーキテクチャと分散インデックス戦略、
低減ゼロのスケーラビリティにより、
低レイテンシ・高精度を保ちながら無駄なリソース消費を抑制できます。
4. 開発者にやさしい環境
PythonベースのサンプルアプリやLangChain連携などが豊富。
開発チームがベクトル検索をすぐに実装可能な環境が整っています。
5. 強固なセキュリティ
RBAC(ロールベースアクセス制御)により、ユーザーや権限の最適な管理と制御が可能。
エンタープライズ環境でも安心して利用できます。
詳しくはこちら:Aerospike Vector Searchのご紹介
業界別ユースケースと活用例
Aerospikeデータベースは、以下のようなユースケースに活用が進んでいます。
- 金融業界:不正検知、信用スコアリング、パーソナライズ投資提案
- 通信業界:リアルタイムのユーザー行動分析とサービスレコメンド
- リテール/EC:チャットボット接客、セマンティック検索、類似商品提案
- 製造/IoT:センサーデータの異常検知、設備同士の関連性分析
どの業界にも共通しているのは、「AIの活用を、既存業務にどう統合するか」という課題。
Aerospikeは、その橋渡しとなるデータ基盤を提供しています。
PoCから本番運用まで、段階的に拡張できる柔軟性
Aerospikeデータベースは、既存の業務データ基盤を壊すことなく、
段階的にAI処理や意味検索機能を追加できます。
①まずはベクトル検索のPoCから
②その後、グラフ分析やNoSQL的な柔軟性も追加
③統合しながら“足し算”で進化できる
その柔軟性と拡張性こそ、今企業が求める「現実的なAI導入」を支える鍵です。
データ基盤選びで失敗しないための3つの視点
AI導入を前提としたデータ基盤の選定は、今や単なる技術選びではありません。
今後の業務の柔軟性・成長性を左右する、経営判断レベルのテーマです。
とはいえ、どのデータベースを選べばいいのか迷う方も多いはず。
そこでここでは、選定を誤らないために重要な3つの視点をご紹介します。
①データの種類と検索要件を明確にする
まずは、自社が扱うデータの種類を棚卸ししましょう。
- テキスト、数値、画像、音声などの種類は?
- 類似検索・キーワード検索・グラフ分析など、どんな検索が必要?
- スキーマは固定か、それとも変化が多いのか?
このように、データの性質と検索方法が明確になると、
「どのモデルをどれだけ組み合わせる必要があるか」が見えてきます。
②単体機能ではなく「全体の業務フロー」で捉える
ベクトル検索やグラフ分析など、個別機能だけで導入を決めるのは危険です。
重要なのは、それらの機能が実際の業務プロセスとどうつながるか。
- 顧客体験のどこにAIが必要か?
- 既存のシステムとの連携はスムーズに行えるか?
- 複数モデルを切り替える必要がある場合、データは分断されないか?
データ活用の“線”を意識し、一貫性のある設計ができるかどうかがカギです。
③拡張性と運用体制を現実的に見積もる
導入がスムーズにいっても、その後の運用でトラブルが起きてしまえば本末転倒です。
- 将来のデータ量の増加に耐えられるか?
- 開発チームのスキルセットとマッチしているか?
- セキュリティ・運用・管理面の体制構築が可能か?
PoC(検証環境)では見えない“本番運用後の世界”を、先回りしてイメージすることが大切です。
この3つの視点を踏まえて選定すれば、「あとから足りなかった」「業務にハマらなかった」
といった失敗を防ぐことができます。
そして、こうした複雑な要件に柔軟に対応できる基盤こそ、
マルチモデル×ベクトルデータベースであるAerospikeデータベースです。
まとめ:単一データベースからマルチモデルデータベースへ
生成AIの普及により、企業のデータ活用はこれまで以上に高度で複雑なものになっています。
「意味で検索する」ベクトル検索はその代表例ですが、
実際の業務では、それだけでは不十分なことがほとんどです。
- 顧客や商品同士のつながりを扱いたい → グラフデータベースの力が必要
- データ形式がバラバラで柔軟に扱いたい → NoSQL的な設計が求められる
- 業務処理・リアルタイム応答・セキュリティまで含めて最適化したい
こうした“掛け合わせ”のニーズが加速する中、今求められているのは──
ひとつの技術ではなく、“複数の技術を自然につなぐ基盤”です。
Aerospikeデータベースは、AI時代のハイブリッドソリューション
- ベクトル/グラフ/ドキュメント/キーすべてを統合
- AI活用と業務処理を、ひとつのデータベースで両立
- スピード、スケーラビリティ、運用性も妥協しない
PoCで終わらせない。
現場で“ちゃんと使えるAI基盤”を本気で考えるなら、
Aerospikeデータベースは選択肢のひとつです。
まずは自社のユースケースで、実現可能性を見てみませんか?
- 「このユースケースでも使えるの?
- 「うちの既存システムと組み合わせられる?
- PoCから本番まで、どのように進めるのがベスト?
そんな疑問にも、専門チームが直接ご相談に乗ります。
ぜひお気軽にお問い合わせください。