現代のデジタル化された世界では、精度の高い検索エンジンがウェブサイトの利便性とユーザーエクスペリエンスを大きく左右します。
Aerospikeは、AIとベクトル技術を活用し、検索エンジンの能力を大幅に向上させることを目指しました。
私たちの目標は、単に正確なキーワードマッチを超えて、ユーザーが真に求める情報を迅速かつ正確に提供することです。
本ブログでは、ベクトルデータベースの構築から、ユーザーフレンドリーな検索インターフェースの設計に至るまで、プロジェクトの全工程にわたるチャレンジとイノベーションを紹介します。
また、これらの改善がどのようにサイト訪問者にとって価値ある結果を提供したかについても深掘りします。
プロジェクトの背景と目的
従来のキーワード検索では、ユーザーのクエリの背後にある意図や文脈を捉えることができませんでした。
そこで私たちは、クエリの深い意味を解釈できるベクトル検索技術を導入することにしました。
この技術は、ユーザーが本当に求めている情報を迅速かつ正確に提供するためのものです。
技術的アプローチと実装
プロジェクトは以下のステップで進行しました:
- データのチャンキングと関連サイトのスクレイピング
- ベクトルインデックスの作成
- キーワードのための逆インデックスの構築
- キーワード検索とベクトル検索の組み合わせ
- 融合アルゴリズムでの結果の再ランキング
- ユーザーフレンドリーな検索インターフェースの設計
- 将来の計画
データのチャンキングとローディング
最初の大きな課題は、ドキュメントを論理的なセクションに分割(チャンク化)し、このデータをAerospikeデータベースにロードする方法を見つけることでした。
幸いにも、以前のデモ(RAG)から多くを学ぶことができ、AerospikeのドキュメントサイトをスクレイピングするためにScrapyを使用しました。
検索の品質は良いデータの取得に依存しています。
そのため、ドキュメントサイトの役立つ部分だけをスクレイピングすることが一つの課題でした。
これに対処するため、サイトの正しい部分を抽出するために詳細なXPathクエリを作成し、検索結果を歪める可能性のある雑多なリンクや関連するが無関係な記事を除外しました。
ベクトルインデックスの構築
検索エンジンのためのインデックスを作成するために、まず、正確で関連性の高い結果を得るために必要なデータを決定しました。
必要なメタデータと各ドキュメントチャンクの処理されたコンテンツです。

私たちのベクトルデータベースでは、各チャンクのタイトル、URL、説明、コンテンツ、インデックス番号を保存しました。
LlamaIndexを使用して各ドキュメントをより小さなチャンクに分割し、Google CloudのVertex AIを使用して各チャンクのタイトル、説明、コンテンツのベクトル埋め込みを生成しました。
さらに、フルテキスト検索のためにタイトル、説明、埋め込みのトークン化されたバージョンとフィルタリングされたバージョンを保存しました。
テキストを正規化するために、spaCyという自然言語処理ライブラリを使用してトークン化、レンマ化、小文字化を行い、一般的なストップワード(例:「what」「where」など)を除去しました。
転置インデックスの構築
私たちがキーワード検索の結果をテストし、評価し始めたとき、キーワードデータを効率的に取得する最も効果的な方法が転置インデックスであることがわかりました。
転置インデックスは、教科書の用語集のように各キーワードを文書セット全体の出現箇所にマッピングします。
Aerospikeのドキュメントからスクレイプした各キーワードの位置を捉えるために、単語レベルの転置インデックスを利用しました。
ユニークなキーワードごとに、そのキーワードが現れた各チャンクを、チャンクID(URLとチャンク番号の組み合わせ)、キーワードの頻度、およびそのチャンク内での位置とともに記録しました。
これらは後に関連性に基づいて結果をランク付けするのに役立つデータです。
検索中に特定のキーワードごとにすべての文書をスキャンする代わりに、逆インデックスを使用してキーワードが存在するすべてのチャンクをすばやく見つけることができ、検索プロセスを大幅に加速しました。
ベクトル検索の実装
Aerospikeは意味検索をシンプルかつ高速にしました。
ベクトルベースの検索を実装するため、まずユーザーのクエリを埋め込み(またはベクトル化)しました。
これにより、クエリがセマンティックな意味を捉えるベクトルに変換され、埋め込み後にAerospike Vector Searchを使用して結果を整形しました。
また、実験を重ねる中で、よくあるクエリの結果をキャッシュすることで速度をさらに向上できることも分かりました。
また、最近使用されたクエリの埋め込みを保存するLRUキャッシュも作成。
これにより、よくあるクエリを再埋め込みする必要がなくなり、意味検索の全体的な効率が向上しました。
キーワード検索の実装
ベクトル検索は意味的に類似した結果を見つけるのに優れていますが、ユーザーが期待する正確な一致や特定のキーワードを見逃すことがあります。
これに対処するため、補完的なキーワード検索を実装しました。
まず、ユーザーのクエリを処理し、spaCyを使用してレンマ化し、ストップワードを除去して、正規化されたキーワードトークンのリストに変換しました。
次に、フィルターされたクエリのすべてのキーワードに対して一括読み取りを行い、以前に構築した逆インデックスを使用して、任意のキーワードが存在するすべての文書を取得しました。
その後、クエリのすべてのキーワードを含む文書のリストを絞り込み、これらの文書に重みを割り当ててランク付けしました。
この重みは、Best Match 25(BM25)ランキングアルゴリズムに基づいて作成され、文書の用語頻度、長さ、逆文書頻度(「Aerospike」や「index」などの一般的な用語を含む結果の「強度」を低減)およびウェブサイト全体の文書の平均長を考慮します。
文書のスコアリングは、キーワードの現れ方に基づいて行われました。
たとえば、タイトルで最も高く、説明でやや低く、コンテンツで最も低く評価されました。
また、検索キーワードが互いに近接している文書には高いスコアを与える近接スコアリングも実装しました。
これらのランキング手順により、最も関連性の高いキーワード結果が最終的な再ランキングに回されました。
ベクトル検索とキーワード検索の両方を組み合わせることで、ベクトル検索で広範囲の文脈と意図を捉えつつ、キーワード検索で明白な一致を見逃さないようにしました。
再ランキング
キーワード検索とベクトル検索から得られた二つの異なる結果リストをどう組み合わせるか、その方法を見つける必要がありました。
ここで再ランキングが登場します。
再ランキングは、二つの独立した検索結果を再評価して再順序付けする第二段階のプロセスです。
再ランキングには多くのアルゴリズムとオープンソースモデルが存在するため、私たちはいくつかを試しました。
最初の試みとしてGoogle Cloudのセマンティック再ランカーを使用しましたが、一般的に処理が遅く、時には関係ない、または奇妙な結果をもたらすことがありました。
これはまるで、元のランキングに対するすべての努力を無にしてしまうかのようでした。
次に、Cohereを試しました。
Google Cloudよりも良い結果が得られましたが、検索パフォーマンスの低下は依然として問題でした。
最終的に、私たちは相互ランク融合(RRF)を採用することに決めました。
RRFは二つのランキングリストを一つに組み合わせ、独立した検索結果が高くランクされたドキュメントに高い最終スコアを与えます。
ベクトル検索とキーワード検索の両方から良い結果が得られたため、RRFは見つけた中で最も効果的な再ランキング方法であり、各検索の長所を組み合わせて最終的な結果リストを強化しました。
フロントエンド
私たちはDocusaurusのUXデザインを気に入っています。
UXデザインには、初期モーダルが表示され、トップ5の結果がポップアップされます。そしてその後の結果を見るためのボタンが設置されています。
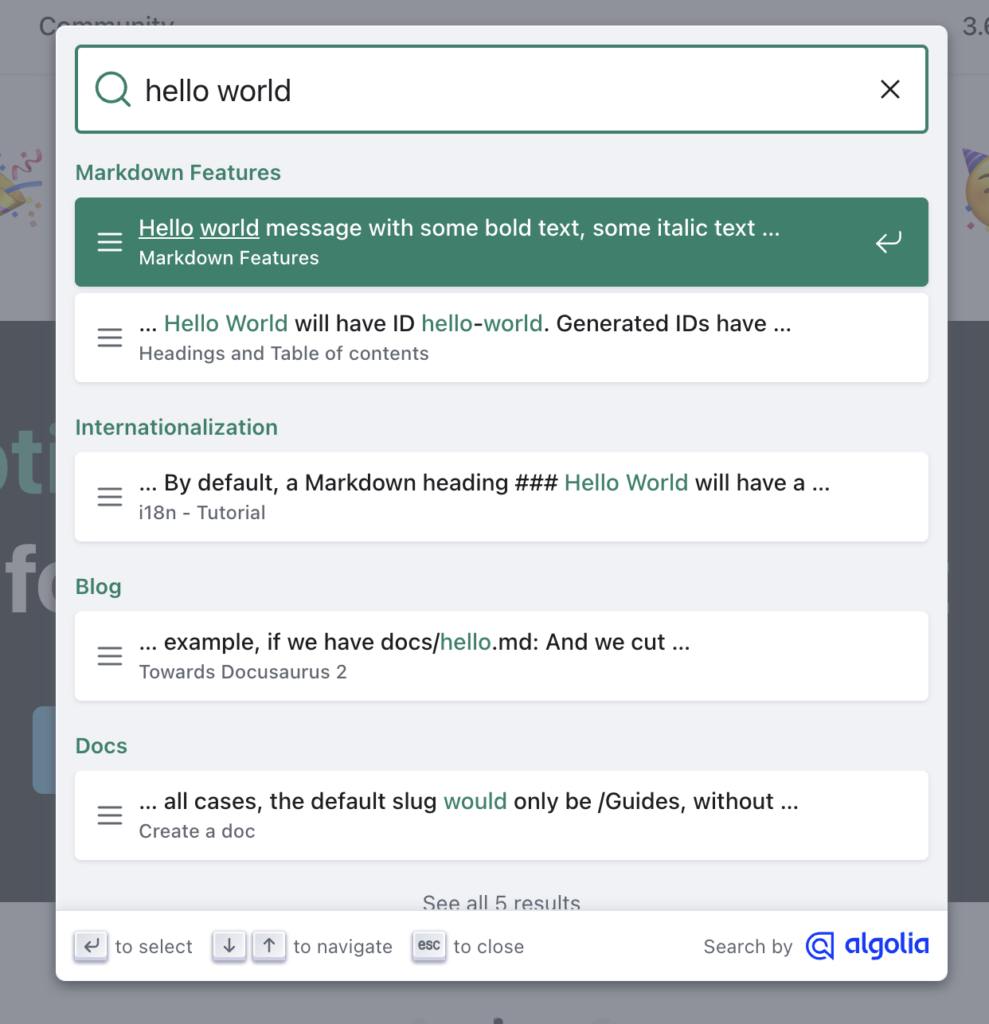
このデザインを私たちの検索体験にも再現しました。
トップ5の結果が非常に関連性が高く役立つため、ユーザーが残りをクリックして見る必要がないというのがコンセプトです。
Aerospikeの今後の展望
これらの作業はすべて始まりに過ぎません。
検索パフォーマンスを改善するための多くの方法がまだあります。
たとえば、検索ユーザーにクエリ関連のチャンクのスニペットを返す、またはAerospikeのウェブサイトをより効率的にスクレイピングする方法を見つけるなどです。
私たちの直近の優先事項は、検索エンジンをAIチャットボットのソースとして使用し、ユーザーがAerospike.comから直接、即座に専門家の回答を得られる会話型エクスペリエンスを作り出すことです。
Aerospike Vector Searchのトライアルはこちら
本ブログは2024年12月12日「How we did it: Enhancing our search engine with AI and vectors」の翻訳です。