生成AIの活用が企業競争力を大きく左右する時代になりました。
その中で、特に注目されている技術が「RAG(検索拡張生成)」です。
ChatGPTやLlama、Claude AIといった大規模言語モデル(LLM)に、
自社固有のデータやナレッジを統合し、より精度の高い回答を生成する仕組みがRAGです。
しかし、現場の担当者の方からは、以下のようなお声もよくお聞きします。
- 導入後のスケーラビリティ問題でシステムがボトルネックに
- 運用コストが予想以上に膨らみ、ROIが見えない
- セキュリティや可用性の要件を満たせず本番導入に踏み切れない
- スケーラビリティ不足でベクトル数が増えるたびにレスポンスが遅くなる
- 検索精度の低さにより、RAGが誤情報や無関係な回答を生成してしまう
- 導入後に運用コストやインフラ要件が想定以上に膨らむ
- LLMとの接続やデータパイプライン構築が複雑で実装が進まない
これらの課題を回避するために最も重要となるのが、ベクトルデータベースの正しい選定です。
本記事では、ベクトルデータベース・グラフデータベースを統合する
マルチモデルデータベースを提供するAerospikeが、RAGとベクトルデータベースの関係から、
選び方のポイント、そしてRAG導入における課題を解決するベストな選択肢「Aerospike Vector」
までをわかりやすく解説します。
RAGとは?ベクトルデータベースの関係
RAGは、大規模言語モデル(LLM)の能力をさらに引き出すための新しいアプローチです。
LLMは自然言語の処理や生成に優れていますが、専門性の高いドメイン知識や
最新の情報を必要とする場合、モデル内部にある学習データだけでは十分な回答が
得られないことがあります。
RAGでは、LLMが外部のコンテキスト情報を参照することによって、
より正確かつ関連性の高い応答を可能にしています。
このプロセスにおいて重要な役割を果たすのが、ベクトルデータベースです。
ベクトルデータベースは、大量のデータから関連情報を瞬時に検索し、
その情報をLLMに提供する仕組みを支えています。
RAGは以下の流れで動作します。
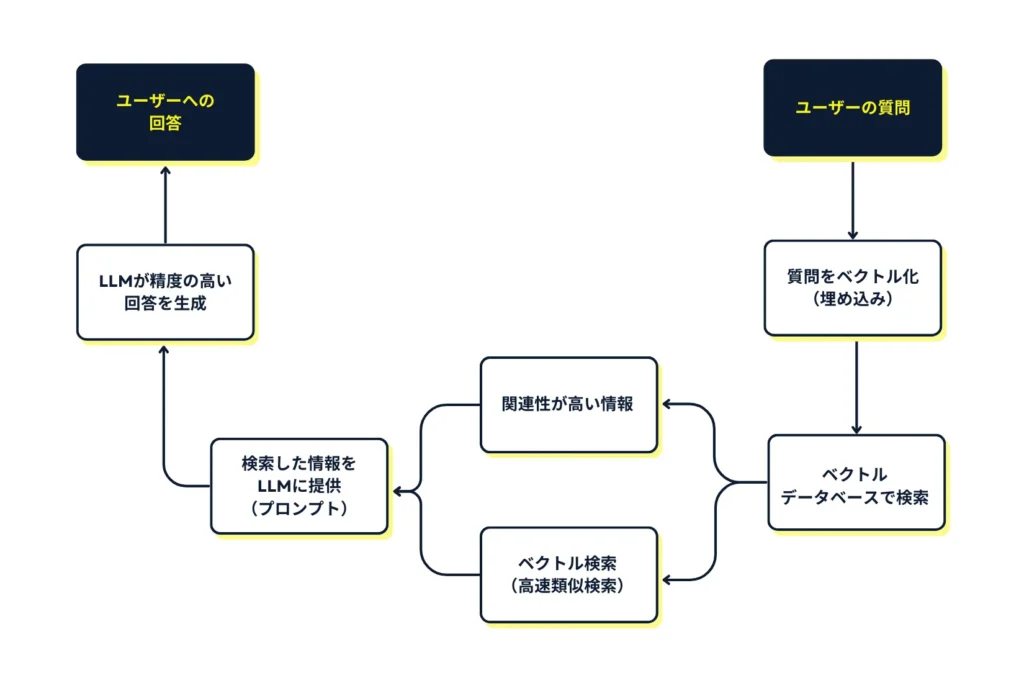
- クエリエンベディング変換:ユーザーの質問や指示をベクトル(埋め込み)に変換
- ベクトル検索:類似度に基づいて関連するドキュメントやデータを検索
- コンテキスト拡充:検索結果をLLMのプロンプトに組み込む
- 回答生成:拡充されたコンテキストを基にLLMが回答を生成
このプロセスにより、LLMが持つ一般的な知識と、組織固有のデータや最新情報を
組み合わせた高精度な回答が可能になります。
ベクトルデータベースが必要な理由
RAGシステムの中核、つまり「検索」の部分を担うのが「ベクトルデータベース」です。
従来のキーワード検索では、「単語の一致・不一致」によるマッチングしか行えません。
しかし、RAGではユーザーの問いや文章の「意味や文脈」を理解し、それに応じた情報を
探す必要があります。
そこで重要になるのが「ベクトル検索」と呼ばれる技術です。
ベクトル検索では、テキストデータを数値(ベクトル)として表現し、ユーザーの質問と
意味的に近い情報を素早く見つけ出します。
このような処理を高速かつ高精度で実現するためには、次の要件を満たすベクトルデータベースが
不可欠です。
- 高速な類似検索を実現できる
- 数百万〜数十億件規模のベクトルデータでもスケールできる
- 検索結果とLLMの生成をリアルタイムで連携できる
つまりベクトルデータベースの性能が、生成AIの精度や応答速度に直結します。
RAG向けベクトルデータベース選定のポイント
ベクトルデータベース選定時には、単に「ベクトル検索ができる」だけでなく、
以下の4点を中心に、業務ニーズに合ったベクトルデータベースかどうかを慎重に
見極める必要があります。
- スケーラビリティ
- 検索性能
- セキュリティと可用性
- 他システムとの連携性
スケーラビリティ
RAGの活用が進むと、扱うベクトルデータの量が急増します。そのため、数百万から
数十億規模のベクトルデータを効率的に処理できるデータベースが求められます。
大量のデータに対応するためには、以下のポイントにも注目する必要があります。
水平スケーリング:データ量やトラフィックが増加した際、サーバーを追加することで
簡単に性能向上が可能であること
ハイブリッドメモリ対応:メモリ(DRAM)だけでなく、SSDやPMEM(Persistent Memory)などのストレージを効率的に活用することで、大量のベクトルをコスト効率よく管理できること
リアルタイム性の維持:大規模環境でもクエリ性能やレイテンシが安定しており、ピーク時でも遅延が発生しにくいこと
検索性能(レイテンシーと精度)
生成AIとリアルタイムで連携するためには、低レイテンシーで高精度な類似検索が不可欠です。
特に対話形式や検索補助機能では、遅延はユーザー体験に直接大きな影響を与えます。
そのため、以下のポイントにも注目しましょう。
リアルタイムクエリ性能:クエリ応答時間が数ミリ秒単位で安定的に維持されること
インデックスの効率性:高度なインデックス技術により、高精度な検索結果を高速に得られること
検索アルゴリズムの最適化:ANN(Approximate Nearest Neighbor)検索などの最適化されたアルゴリズムを活用し、精度とスピードを両立できること
セキュリティと可用性
RAGで使用するデータには、社内ナレッジや顧客情報など機密性の高い情報が含まれることが
多いため、アクセス制御、暗号化、可用性を確保するアーキテクチャが必要です。
安全な運用をするには、以下の要素も考慮する必要があります。
アクセス制御・認証:ロールベースのアクセス制御(RBAC)やLDAP、OAuthなどによる厳密なユーザー認証・権限管理が行えること
データの暗号化:転送中および保存中のデータを暗号化する仕組みを標準装備していること
高可用性:障害発生時にもサービスを継続できるよう、冗長構成や自動フェイルオーバー機能を備えていること
災害復旧(DR)機能:地理的に離れた複数のデータセンター間でレプリケーションが可能で、データ損失や長期停止を回避できること
他システムとの連携性
LLMや既存のデータ基盤(データレイク、DWH、APIなど)とスムーズに連携できることも、
データベース選定の重要なポイントです。
RAGは単独で動作するシステムではなく、既存のインフラやアプリケーションとの連携を前提と
しています。そのため、以下のポイントにも注目して選定する必要があります。
LLMフレームワークとの統合性:LangChainやLlamaIndexなど、主要なLLMフレームワークとシームレスに接続可能であること。これにより、モデルとデータベース間のやりとりが効率化され、開発期間の短縮が期待できます。
既存データ基盤との相互運用性:現在稼働しているデータレイクやデータウェアハウス(Snowflake、Databricks、AWS S3等)との相性がよく、データのインポート・エクスポートが容易であること。これにより、RAGに必要な情報をリアルタイムでアップデートすることが可能となります。
標準APIのサポート:REST APIやgRPC、各種SDKをサポートしていることにより、他のアプリケーションとの迅速な統合や柔軟なカスタマイズが可能になります。
代表的なベクトルデータベースのユースケース
ここでは、企業でRAG ベクトルデータベースがどのように活用されているのか、業界別ユースケースをご紹介します。
1. 金融業界でのRAG ベクトルデータベース活用
ユースケース:コンプライアンスと規制文書の自動検索
金融機関では、膨大な量の規制文書、ポリシー、内部手順書などを管理しています。
RAG ベクトルデータベースを導入することで、以下のような効果が得られます。
- 複雑な規制に関する質問に対して、関連文書から正確な情報を抽出して回答
- コンプライアンスチェックの自動化と監査証跡の確保
- 新規規制の導入時に、既存ポリシーへの影響を分析
2. 製造業でのRAG ベクトルデータベース活用
ユースケース:技術ドキュメントとナレッジ管理
製造業では、製品仕様書、設計図、トラブルシューティングガイドなど、膨大な技術文書が存在します。RAG ベクトルデータベースの導入により下記が可能になります。
- エンジニアが過去の設計情報や解決策を素早く検索可能に
- 新人エンジニアの知識習得と意思決定をAIがサポート
- 製品開発の過程で発生したノウハウの効率的な活用
3. ヘルスケア分野でのRAG ベクトルデータベース活用
ユースケース:医療研究と診断支援
医療機関や製薬企業では、論文、臨床試験データ、患者記録などの大量のデータを扱います。RAG ベクトルデータベースによって、
- 最新の医学研究と患者データを組み合わせた診断支援
- 類似症例の検索と治療法の効果予測
- 薬剤相互作用や副作用に関するエビデンスベースの情報提供
Aerospike Vectorで解決できる課題とは?
以上から、「RAGの成功には高性能かつスケーラブルなベクトルデータベースが欠かせない」ということがお分かりいただけたのではないかなと思います。
ここからは、Aerospike Vectorが実際のRAGユースケースでどのような課題を解決するのかを、3つのポイントに整理してご紹介します。
Aerospike Vector最大の特徴は、高速なベクトル検索に加え、キー・バリュー、ドキュメント、グラフといった複数のデータ形式を同時に扱える点です。
例えばEコマースにおいては、ベクトルにて関連商品を推奨し、グラフによる購買履歴によって、より消費者の好みに応じた商品の推奨、基本データはキーバリューにて管理することができます。
このようにAerospike単体で様々なデータ活用ニーズに応えることが可能です。
そのため、多様なユースケースに対応することができ、リアルタイムな生成AIアプリケーションを柔軟に構築します。
① 検索精度とリアルタイム性の強化(パフォーマンス)
Aerospike Vectorは、超高速なデータアクセスと並列処理を特徴としています。そのため、大量のベクトルデータの中から意味的に最も関連性の高い情報を即座に抽出できます。
一般的なベクトルDBでは困難なミリ秒単位の応答を実現し、対話型のRAGシステムでもストレスのない迅速なレスポンスを可能にします。この高速処理能力が、回答の精度と即時性を格段に高めます。
② 大規模データ処理への対応力(スケーラビリティ)
RAGの運用が進めば、扱うベクトルデータは急速に増加します。
Aerospike Vectorは分散アーキテクチャを採用しているため、数百万〜数十億規模のベクトルデータに容易に対応することが可能です。
そのため、将来的なデータ増加に応じてサーバーを追加することで、性能劣化なく拡張でき、安心して長期運用することができます。
③ エンタープライズレベルのセキュリティと信頼性(セキュリティ)
RAGで取り扱うデータには、社内の重要なナレッジや顧客の個人情報など、厳重なセキュリティ対策が求められるものが多く含まれています。そのため、Aerospike Vectorでは以下のような堅牢なセキュリティと高い信頼性を備えた機能を標準で提供しています。
- ロールベースアクセス制御(RBAC)
- エンドツーエンドの暗号化
- 柔軟な認証・認可機能
- 高可用性構成による業務継続性
これにより、企業が安心して本番環境でRAGを導入・運用できます。
Aerospike Vectorが最適な理由

RAGシステムの中核となるベクトルデータベースには、さまざまな選択肢が存在します。
実際に、他のベクトルデータベースと比較した際に、なぜAerospike VectorがRAG用途に最適なのかを3つの観点から解説します。
① Vector only型 vs. マルチモデル型
現在、多くのベクトルデータベースはvector only型、つまりベクトル検索に特化した設計になっています。
一方、Aerospike Vectorはマルチモデル型で、ベクトル検索だけでなく以下のような多様なデータ処理に対応します。
このように、ベクトル+構造化データの同時処理が可能な点は、RAGの高度な要件において大きなメリットとなります。
例えば、ベクトルにおけるRAGだけでは精度が不足している専門領域にRAGにおいてはグラフRAGと組み合わせたハイブリッドRAGが有効ですが、AerospikeはそのようなハイブリッドRAGにも対応が可能です。
② Aerospike Vectorならではの強み
Aerospike Vectorが他製品と一線を画す理由は、主に4つあります。
インデックス性能: SSD/メモリのハイブリッドストレージにより、インデックス作成や再構成が高速かつ安定
リアルタイム性:データの更新・追加を即座に検索に反映できるため、「常に最新のナレッジ」でRAGが動作可能
高可用性と耐障害性:エンタープライズ対応の分散設計で、業務クリティカルな用途でも安心
一貫したアーキテクチャ:RAGに必要な「検索」「生成」「外部連携」が単一プラットフォーム内で完結
これにより、別途ミドルウェアや複雑なデータパイプライン構築をせずにRAGが実現できるのが、Aerospike Vectorです。
③ RAGに特化した設計思想
Aerospike Vectorは、単なるベクトル検索エンジンではなく、RAGの現場課題を解決するために設計された製品です。
RAGに求められる要件とは:
- 意味的な類似検索の精度とスピード
- 常に更新され続けるドキュメントへのリアルタイム対応
- 生成AIのリクエストに対して低レイテンシで応答する性能
- セキュアかつスケーラブルなデータ基盤
これらをすべて満たすベクトルデータベースは、実は限られています。
Aerospike Vectorは、リアルタイム性・運用のしやすさ・拡張性・セキュリティのすべてを備えた、まさにRAG時代のためのデータベースです。
まとめ:RAG構築には最適なベクトルデータベースが欠かせない
生成AIを業務に本格導入するうえで、RAGは不可欠な技術となりつつあります。
そして、そのRAGの性能を大きく左右するのが、ベクトルデータベースの選定です。
本記事では、
- RAGとベクトルDBの基本的な関係
- 選定時のポイントとよくある落とし穴
- ベクトルデータベースのユースケース
- Aerospike Vectorによる課題解決
- 他製品と比較したAerospike Vectorの優位性
などを通して、RAG導入・運用における成功の鍵をご紹介してきました。
RAGを活用して、社内ナレッジの有効活用や顧客対応の自動化を進めたい。
そう考えるIT担当者にとって、「どのベクトルデータベースを選ぶか」は大きな戦略的な意思決定とも言えるのではないでしょうか。
ぜひ、一度私たちに相談してみませんか?
是非お気軽にお問い合わせください。