ベクトルとは、機械学習モデルが言語、画像、動画、音声を生データとして表現する方法です。
これらの大きな配列は線形代数を活用して、言語モデル、画像認識システム、生成的AIアプリケーションのパターンを組み立てるのに効果的です。
そのため、AIアプリケーション開発に興味を持つ技術者の想像力をかきたてています。
「メモリー」や「コンテキスト・ウィンドウ」といった新しい生成システムのコンセプトは、言語モデルの能力を増強するためにベクトル・データベースを使用する特定のアプリケーションを指します。
間違いなく、次世代のデータベース・テクノロジーは大量のベクトル・データを扱わなければならないが、これをスケーラブルでコスト効率に優れ、生産に適したものにするにはどうすればいいのでしょうか。
私たちが新しいベクトル研究開発プロジェクト、「プロキシマス」を立ち上げたときに答えを出そうとした質問です。
私たちは、ベクトル・データベースのニーズを理解するために、何十人ものAIビルダー、企業の機械学習(ML)チーム、データベース運用を専門とするサイト信頼性エンジニア(SRE)と話をしました。
本ブログでは、これらの会話から得られたインサイトについてご紹介します。
機械学習チームは本番稼動に苦労している
ジェネレーティブAI分野のエキサイティングな現実は、説得力のあるデモウェアを簡単に構築できることです。
公開されているモデルとデータセットを使って、わずか数日で、Google画像検索のマジックのような画像検索アプリケーションを構築しました。
その上、検索拡張世代(RAG)アプリケーション、セマンティック検索、レコメンデーションシステム、その他多くの一般的なアプリケーションパターンの例が、無料で自由に利用することができます。
これらはすべてMLモデルとベクトルに依存しています。
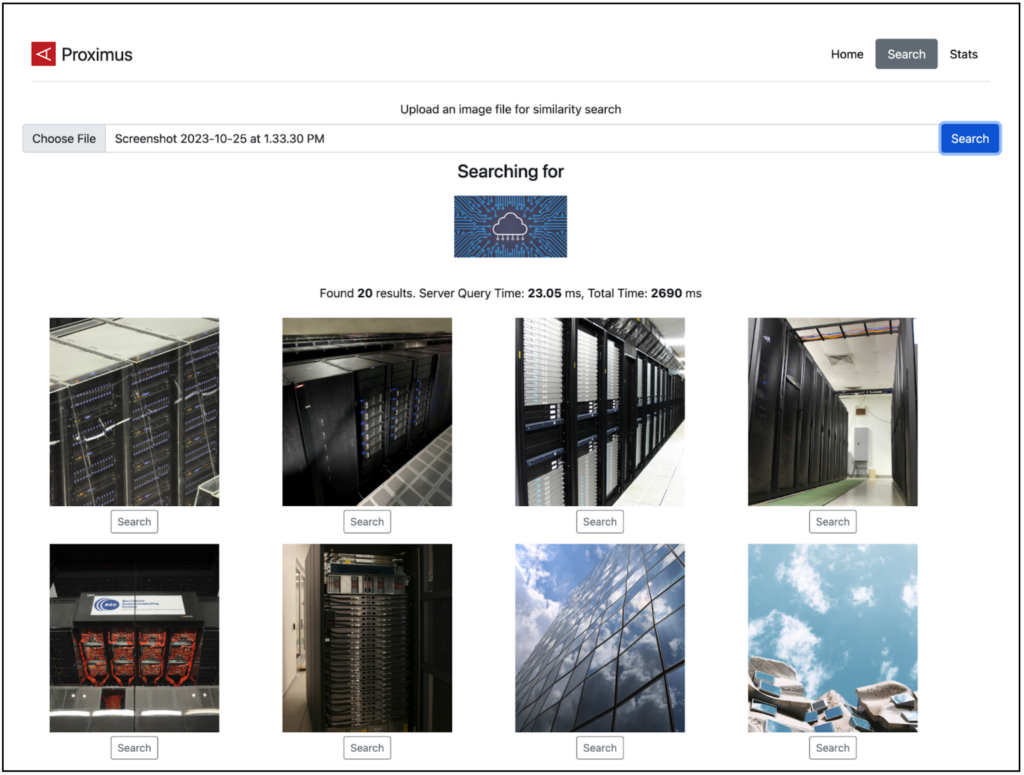
小規模なデータでもベクターの構築にはコストがかかる
ベクター展開は小さなデータであっても高額です。
チームがいまだにデモ導入にとどまっている主な理由は、コストが大きくなる可能性があるからです。
小規模なデータセットでも、クラウドやAI関連のサービスプロバイダーから莫大な費用を請求されることがよくあります。
私たちは、比較的小規模なデータセットのために数百万ドルのクラウドクレジットを使用したチームと話をしたことがあります。
さらに、利便性の良さからベクター検索サービスを利用しているものの、大規模な展開のためにスケールアップする余裕がないチームも多いと聞きます。
Postgres、Redis、Elasticのような既存のよく知られたデータベースへの拡張は、多くの場合コスト削減には役立つものの、パフォーマンスと品質のトレードオフが存在します。
全体的なコストは、システムの構築方法にもよりますが、通常、100万ベクトル埋め込みあたり数百ドルから数千ドルです(つまり、1ドルあたり1万ベクトル)。
これは特定のシナリオには適しているが、数十億ベクトル規模のユースケースであれば、運用コストは数十万から数百万ドルになります。
現在のベクター検索は高スループットに対応できない
驚くことではないが、このような高コストは、スループットが極端に制限されたシステムとともにもたらされます。
一般的なシステムでは、毎秒数百のクエリー(QPS)しか処理することができません。
さらに、Pineconeのようなサービスでは、インジェスト用に特別にスケールアウトする必要があり、データセット全体で最大10k QPSになります。
要するに、プロダクションレディのモデルであっても、それをスケールしてデプロイすることができない可能性があるのです。
実際の例として、効果的な詐欺検出システムを開発した有名なeコマースブランドと話をしましたが、そのシステムをユーザーセッションの1%未満でしか実行できませんでした。
問題は、ユーザー・セッションの1%未満しか実行できなかったことです。
我々が話を聞いた他のチームは、このようなスループットの制約に対処するために社内でプロジェクトを立ち上げていると話していました。
AIアプリケーションには、ベクトル以上のデータベースニーズがある
コスト、スループット、生産性の制約から、MLモデルの展開はベクター検索とモデル実行だけでは不十分です。
MLチームは、モデルを本番稼動させることに成功した場合、提供するモデルの側面だけに焦点を当てるのではなく、アプリケーションを全体的に考えることが一般的です。
高性能なフィーチャーストアの使用、フィルタリング技術、UXの考慮は、本番稼動に成功するチームとそうでないチームを分ける要因の一部です。
モデルの利用可用性が重要な変化をもたらす
AI採用の主な原動力は、ベクター・データベースや新しいアプリケーション設計パターンと並ぶMLモデルです。
これらの分野でそれぞれに目覚ましい革新がありましたが、過去18ヶ月で世界を変えたのは、オープンモデルとサンプルアプリケーションが利用可能になったことです。
ChatGPTが注目されるのは当然ですが、オープンソースモデルの普及と開発スピードも同様に驚異的です。
現時点で、Hugging Faceには40万以上のモデルを提供しており、そのほとんどがオープン・ライセンスです。
つまり、テキスト生成、画像認識、あるいはロボット工学のための既製の機能をアプリケーションにプラグインできるのです。
強力なコーディング・スキルや高性能GPUは、これらの新技術を試すための前提条件ではない。
強力なコーディングスキルや高性能GPUは、これらの新技術を試すための必須条件ではありません。
LLM Studioを使ってGUIからモデルをダウンロードしてインストールしたり、LLM CLIを使ってCLIPモデルを使ってテキスト検索のために自分の写真にインデックスを付けることもできます。
これらのツールを使用すると、これらの利用可能なモデルを使って構築することが、多くの企業ユースケースにとって明白な選択肢になることが明確になります。
構築の時期
この1年のAIの発展には目を見張るものがあり、数え切れないほどの新しい機会が開かれ、多くの既存の障壁が取り除かれました。
スケールの大きなベクトルは、これらのユースケースを解放し、企業、ユーザー、社会に新たな価値を生み出すことができます。
計算能力も急速に変化しており、ハイパワーGPUの利用可能性と需要が高まっています。
ここでデータベースが果たすべき役割は、より平凡なものに見えるかもしれないし、小規模なデモや概念実証プロジェクトにとっては些細なことでさえあるかもしれません。
しかし、AIアプリケーションを大規模に本番稼働させる企業にとっては、規模、スループット、コスト効率など、いくつかの馴染みある課題が発生します。
これらは身近な問題ですが、最終的には、イノベーションによってインフラのコストが下がり、新しいアプリケーションパターンが一般的になるでしょう。
このブログは、2023年12月6日のブログ「Five observations from enterprises using vectors to build AI applications」の翻訳です。