世界的なGPU不足は、COVID-19の影響による供給網の混乱、デバイス需要の増加、暗号通貨マイニングの拡大によって引き起こされ、高性能コンピューティングに依存する企業や個人に大きな課題をもたらしています。
サプライチェーンの寸断、デバイス需要の増大、暗号通貨マイニングの急増により、グラフィックス・プロセッシング・ユニット(GPU)の供給が不足しました。
さらに、生成AI(GenAI)や大規模言語モデル(LLM)の登場により、膨大な計算能力が必要となり、GPUの供給にさらなる負担がかかっています。
CPUとGPUの特徴を理解し、機械学習パイプラインを最適化することが、より効率的なリアルタイムデータ処理の鍵となります。
本ブログでは、各ハードウェアの役割、パフォーマンス向上のための工夫、そしてAerospikeが提供する低レイテンシーソリューションを紹介。
GPU不足に負けないML運用のヒントを探ります。
CPUとは
中央処理装置(CPU)は、一般的に「コンピュータの頭脳」と呼ばれ、単純なコマンドの実行から複雑なソフトウェアプログラムの実行まで、幅広いタスクを処理するために設計された汎用プロセッサです。
CPUは通常、シーケンシャル処理に最適化された少数の強力なコアで構成されており、Webブラウジング、文書作成、オペレーティングシステムの実行など、高精度かつ低レイテンシーを必要とするタスクにおいて優れた性能を発揮します。
CPUの各コアは、1つのスレッドの命令を一度に実行することができ、個々の計算を迅速に行う必要があるタスクに非常に効果的です。
MLの文脈では、CPUはデータの前処理、特徴量エンジニアリング、軽量なモデルの推論などのシーケンシャルなタスクに最適です。
特に小規模なデータセットを扱う場合、CPUはGPUの並列計算能力には及ばないものの、高速なオペレーションの切り替えやランダムアクセスメモリパターンの処理に優れています。
最新のCPUは複数のコアを持ち、複数のキャッシュレイヤーによってデータアクセスと処理速度を最適化しています。
これにより、メインメモリからのデータ取得にかかる時間を短縮し、低レイテンシーを実現します。多くのMLワークフローでは、データの前処理や探索的データ分析(EDA)の段階でCPUが使用され、汎用的な計算タスクを低レイテンシーで処理する能力が活かされます。
また、大規模な並列処理を必要としない小規模なモデルや推論タスクにおいては、コスト効率が高く効率的な選択となります。
GPUとは
一方、グラフィックス処理装置(GPU)は、もともとゲームやビジュアルアプリケーションにおけるグラフィックスのレンダリングを加速するために設計された特殊なプロセッサです。
しかし、現在ではその役割が大幅に拡大し、特に並列処理を必要とするさまざまな計算集約型タスクにおいて重要な役割を果たしています。
MLの文脈では、GPUは大規模なモデルのトレーニングにおいて欠かせない存在となっており、複数の演算を同時に処理する能力を持っています。
CPUがシーケンシャル処理を前提に設計されているのに対し、GPUは数千の小さく効率的なコアで構成され、多くの計算を並列に実行できます。
このアーキテクチャは、行列計算や大規模データセットを伴う操作に理想的で、ディープラーニングや他のMLアルゴリズムでよく見られます。
多数のコアが協力してデータを並列に処理し、大規模なMLモデルのトレーニング時には、数十億の演算を毎秒で実行することが可能です。
GPUアーキテクチャのもう一つの重要な特性は、メモリレイテンシーをCPUよりも効果的に処理できる点です。
CPUがキャッシュレイヤーに大きく依存して低レイテンシーを維持するのに対し、GPUは大部分のトランジスタを計算に割り当てており、メモリからのデータ取得にレイテンシーが生じても並列計算を行うことができます。
この特性により、大量のデータを迅速に処理する必要があるディープラーニングやAIトレーニングなどのタスクにおいて、GPUが最適な選択肢となります。
CPUとGPUを取り巻く環境
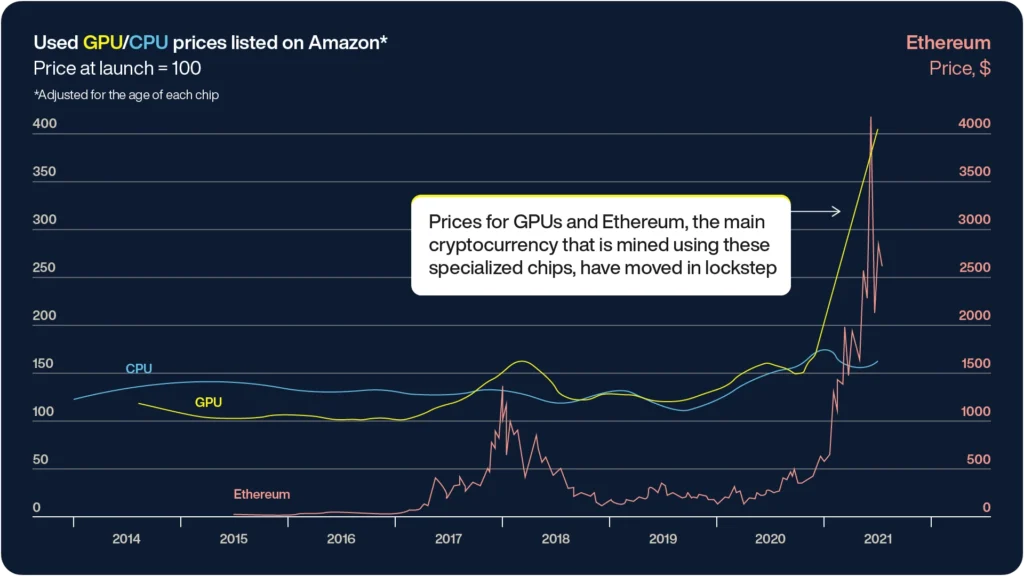
OpenAIのGPT-4は、約25,000台のNVIDIA A100 GPUを用いて100日間にわたってトレーニングされ、コストは約1億ドルに達しました。
この需要はさらに強まっており、機械学習(ML)プロジェクトに必要なハードウェアへのアクセスが困難になっています。
GPUは特に並列処理に優れた性能を発揮し、複雑なモデルのトレーニングにおいて優れたパフォーマンスを提供しますが、現在の不足状況においては必ずしも最もコスト効率が高いとは限りません。
多くの組織が、リアルタイム推論などの特定のタスクにおいて、より入手しやすくコスト効率の高い中央処理装置(CPU)を活用することで、MLプロジェクトのスケーリングを続ける方法を模索しています。
CPUとGPUのアーキテクチャと用途
GPUアクセラレーションコンピューティングは、CPUとGPUの両方を活用して、ディープラーニング、分析、3Dモデリングなどの処理タスクを実行する手法です。
このアプローチでは、計算負荷の高い処理をGPUが担当し、その他のコードは主にCPUで実行されるため、全体的なパフォーマンスが最適化されます。
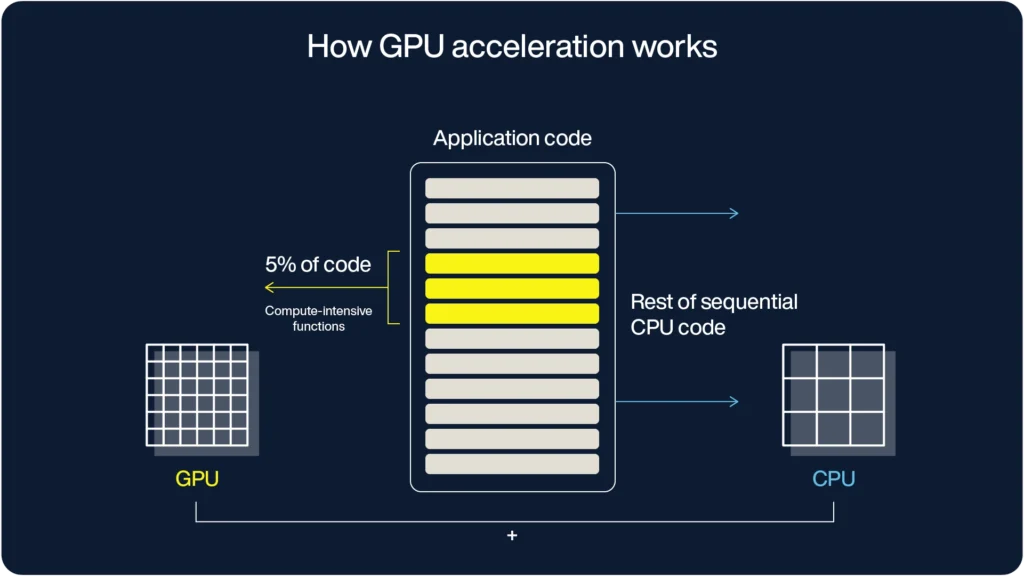
CPUアーキテクチャ
コア構造:CPUは、汎用的なシーケンシャル処理に最適化された少数のコアで構成されています。
最適化:CPUは可能な限り低いレイテンシでタスクを完了するよう設計されており、迅速にオペレーションを切り替えることができます。
キャッシュシステム:
• レイヤー1(L1)キャッシュ:各CPUコアはデータと命令の専用のL1キャッシュを持っています。
• レイヤー2(L2)キャッシュ:L1より大きくて少し遅いL2キャッシュは、個々のコアをサポートします。
• レイヤー3(L3)キャッシュ(最終レベルキャッシュ、LLC):複数のコアに同時にサービスを提供する共有キャッシュレイヤーです。
メモリ取得:キャッシュレイヤーにデータが存在しない場合、CPUはメインメモリからデータを取得し、効率性を保つために低レイテンシアクセスを優先します。
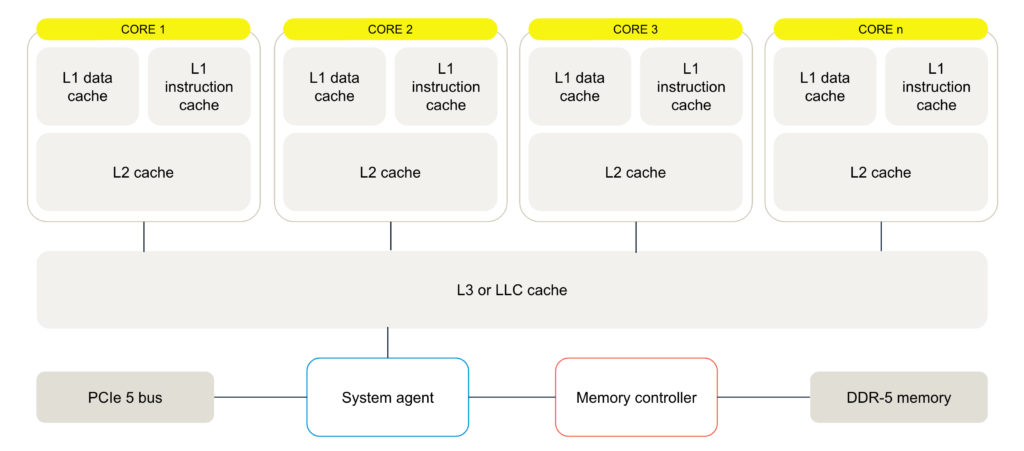
GPUアーキテクチャ
並列アーキテクチャ:GPUはスループットに最適化されており、数千の効率的なコアからなる大規模な並列アーキテクチャを持ち、複数のオペレーションを同時に処理できるよう設計されています。
コア構造:
• ストリーミングマルチプロセッサ(SM):GPUはSMからなるプロセッサクラスターを含み、各SMに複数のコアがあります。
• CUDAコア:NVIDIAのGPUでは、これらのコアはCUDAコアと呼ばれ、複雑なAIアルゴリズムを処理するための算術論理ユニット(ALU)を持っています。
キャッシュシステム:
• 専用L1キャッシュ:各SMは、命令に迅速にアクセスするためのL1キャッシュを持つことが一般的です。
• 共有L2キャッシュ:SMは、高速メモリにアクセスする前に共有L2キャッシュを利用します。
メモリレイテンシ耐性:CPUとは異なり、GPUはより高いメモリレイテンシを許容するよう設計されており、トランジスタの多くをキャッシュではなく計算に割り当てています。このアーキテクチャは、メモリアクセスが遅くても並列計算を維持することに重点を置いています。
CPUとGPUの主な違い
CPUとGPUには次のような違いがあります。
処理の最適化
• CPU:低レイテンシのシーケンシャル処理に最適化。
• GPU:高スループットの並列処理に最適化。
コア機能
• CPUコア:汎用的なコアで、幅広いタスクを迅速に切り替えて処理するのに優れています。
• GPUコア:AIやグラフィックス処理など特定のタスクに特化した(CUDAコアなど)コアです。
メモリシステム
• CPU:高速なデータ取得のためにキャッシュレイヤーに大きく依存します。
• GPU:並列計算に重点を置き、キャッシュレイヤーが少なくてもレイテンシを許容します。
MLワークフローにおけるCPUとGPUの使い分け
CPUとGPUのどちらを選ぶかは、プロジェクトの具体的な要件に依存します。
それぞれのプロセッサは異なるタスクで優れており、どのタイミングでどちらを使用するかを理解することで、パフォーマンス、コスト、速度を最適化できます。
以下では、MLパイプラインの各段階でどのハードウェアを活用するべきかを解説します。
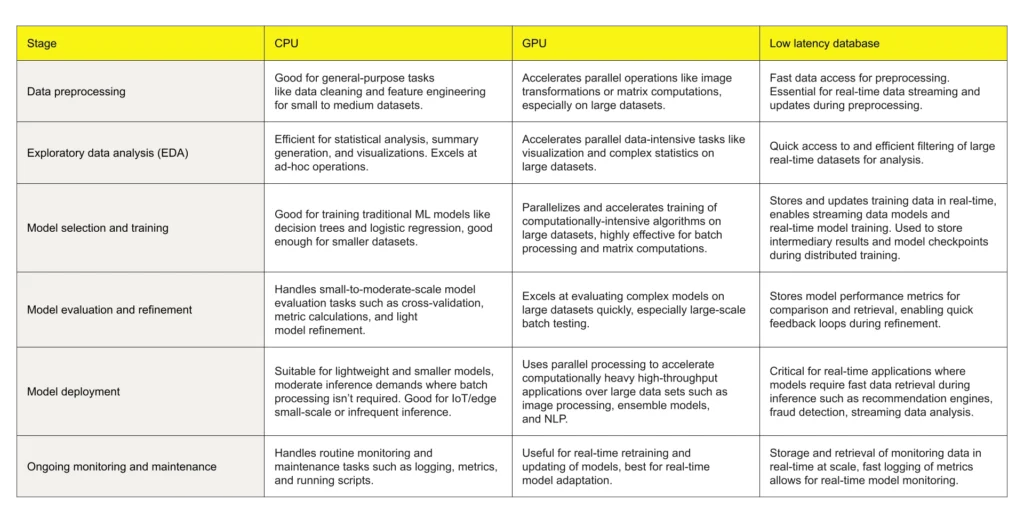
GPUリースだけではリアルタイムMLパイプラインの最適化は不十分
GPUがMLにおいて注目されているものの、効率的なワークフローは高価(かつ不足しがちな)GPUを凌駕することがあります。
実際、AIパイプラインの大部分はモデルのトレーニングや実行よりもデータの管理に多くの時間を費やします。
GoogleやMicrosoftなどは、モデルのトレーニング時間の70%がデータの取得、クリーニング、整形に使われると推定しています。
複数の段階でのデータ転送はレイテンシを生み、貴重なGPUリソースを無駄にします。
多くの小さなファイル(少数の大きなファイルに対して)がAIパイプラインを遅くし、GenAI/RAG/LLMのトレーニングでは多くの小さなファイルが必要です。
多数の小さなファイル(数百万の小さな画像、デバイスごとのIoTログ、取引ごとの顧客データベースログなど)の取り込みは、大量のメタデータを生み出します。
MLのメリットを最大化するには、データパイプラインのボトルネックを排除する必要があります。
Aerospikeは、トレーニングと推論におけるデータ転送時間を最小限に抑え、データ分析能力を向上させます。
リアルタイムMLパイプラインにAerospikeを導入するメリット
• レイテンシの削減:Aerospikeにモデルパラメータを保存することで、データ移動を最小限に抑えながら推論リクエストを処理し、応答時間を短縮します。
• スケーラビリティ:水平スケーリングにより、クラスタにノードを追加するだけで推論負荷の増加に対応可能です。
• コスト効率:推論に高価なGPUではなくCPUを活用することで、ハードウェアコストを大幅に削減しつつ、高いパフォーマンスを維持できます。
• リアルタイム更新:Aerospikeはリアルタイムデータの更新に対応しているため、モデルパラメータや特徴量をダウンタイムなしで継続的に更新し、モデルの改善を可能にします。
• 高スループット:Aerospikeは1秒あたり数百万件のトランザクションを処理できるため、高ボリュームの推論に最適です。
GPU不足がMLの進展を妨げることはありません。
Aerospikeはモデルの構築、トレーニング、デプロイを加速させます。リアルタイムデータの力を活用し、GPUの待ち時間を解消しましょう。
リアルタイム機械学習にはリアルタイムデータプラットフォームが必要
リアルタイムMLは、高速データ取り込みを可能にし、MLモデルが迅速な意思決定を行うために超低レイテンシーのデータベースを必要とします。
AIリーダーは、新しいデータを高速で処理し、推奨エンジンや不正検知といったタスクにおいてMLモデルにタイムリーかつ関連性のある情報を提供できるデータベースに注目しています。
リアルタイムパフォーマンスのためのML最適化
MLモデルを本番環境で動作させるには、低レイテンシのデータアクセスが必要です。
シームレスなユーザー体験を実現するために、モデルはモデルプルーニングなどの技術で迅速な推論に最適化され、データインフラは効率的なキャッシング、ロードバランシング、オートスケーリングを備え、トラフィックの変動に対応する必要があります。
リアルタイムMLにおけるAerospikeの役割
Aerospikeは、超低レイテンシーデータベースのリーダーとして、ほぼ10年間MLアプリケーションのデータ基盤を提供してきました。
PayPalやBarclaysでは不正検知、Wayfairでは推奨、Flipkart、Myntra、AppsFlyerでは多様なMLユースケースで利用されています。
Aerospikeのハイブリッドメモリアーキテクチャ(HMA)はサブミリ秒のデータアクセスを実現します。
DRAMの速度とSSDのコスト効率を組み合わせ、大規模なデータ処理やリアルタイム意思決定に最適です。
成長するデータニーズに対応するスケーラブルなアーキテクチャ
Aerospikeのアーキテクチャは数十億件のレコードやペタバイトのデータにスケール可能で、パフォーマンスを維持します。
分散型でマルチスレッド設計が施されており、大規模なデータセットでも応答時間を低く保ちながら、ハードウェアの必要性を低減します。
MLフレームワークとのシームレスな統合
Aerospikeは、Aerospike Connect for Sparkなどの人気のMLツールと統合され、データの読み込み、変換、モデルのトレーニングをサポートします。
この互換性により、既存のワークフローに簡単に導入でき、データ探索やML開発の速度が向上します。
リアルタイムアプリケーション向けの高速データアクセス
Aerospikeのインデータベース処理および低レイテンシーの特徴ストア機能は、データの移動を削減し、モデルの反復を加速します。
リアルタイムの不正検知やチャットボットのようなユースケースでは、Aerospikeは関連データへの即時アクセスを提供し、最小限のレイテンシーで迅速かつパーソナライズされた応答を可能にします。
本ブログは2024年10月17日「CPU vs. GPU: What’s best for machine learning?」の翻訳です。