AIや機械学習の進化に伴い、ベクトルデータベースは非構造化データの管理と検索において重要な役割を果たしています。
本記事では、ベクトル・グラフデータベース統合の「マルチモデルデータベース」を提供するAerospikeが、ベクトルデータベースの基本概念、機能、実際の応用例、そして適切なデータベースの選び方について詳しく解説します。
あわせて読みたい:ベクトルデータベースのおすすめはどれ?|生成AI・LLMに最適な選び方を解説
ベクトルデータベースとは?
ベクトルデータベースは、データを数値ベクトルとして保存し、インデックスを作成します。
従来のリレーショナルデータベースは、行と列を使って構造化データを効率的に保存するよう設計されています。
一方、NoSQLデータベースは、グラフやキー・バリュー型、ベクトルなど、さまざまなデータモデルをサポートし、非構造化データを扱うことができます。
ベクトルデータベースは、速度と精度を求めるユースケースに適しているため、企業にとって非常に有益なデータベースです。
これらのデータベースは、ベクトル埋め込みを多次元空間に保存し、ベクトル計算を通じて類似性を計算することを可能にします。
従来の検索手法は、厳密な一致やファジーロジックに頼っていましたが、ベクトルデータベースを使えば、構造化データと非構造化データの両方を効果的に活用できます。
生成AIにとってベクトルデータベースが欠かせない理由
前述のように、生成AIはテキストや画像などの非構造化データを扱い、それをもとに高品質な応答を生成します。
ベクトルデータベースは、こうした非構造化データを「意味」を持つベクトルとして保存・検索し、高速かつ精度の高い情報取得を可能にします。
特に、RAG(Retrieval-Augmented Generation)モデルでは、ユーザーの質問に応じて関連情報を検索し、正確な回答を生成するため、ベクトルデータベースが不可欠です。
そのため、生成AIがより自然で信頼性のある応答を実現するには、ベクトルデータベースが基盤技術として重要な役割を果たします。
高まるベクトルデータベースのニーズとメリット
様々な分野においてベクトルデータベースに対する関心の高まりは顕著であり、2028年までにその世界市場は43億ドルに達すると予想されています。
また、ガートナーによると、経営者の45%が、ChatGPTのような生成AIチャットボットに刺激を受けて、AIへの投資を増やしているということです。
さらに、2024年3月にBARCが発表したレポート「Optimizing Your Architecture for AI Innovation」によると、エンタープライズでのベクトルデータベースの導入状況は次のようになっています。
- 20%の企業が、すでに本番環境でベクトルデータベースを使用しています。
- 26%がテスト段階にあります。
- 29%が導入の可能性を調査しています。
- 24%が導入の計画を立てていません。
競争力を維持するためには、企業はベクトルデータベースに対する理解と採用を加速する必要があります。
ベクトルデータベースのメリット
ベクトルデータベースを導入するメリットがあるのでしょうか。
1. 意味に基づく検索が可能
ベクトルデータベースでは、キーワード一致ではなく、データの意味やコンテキストを理解した検索ができます。そのため、類似したアイデアや関連性の高い情報を正確に取得することができます。
例:「ランニングに最適な靴」という検索に対し、「ジョギング用スニーカー」など関連する結果を返せる
2. 高速な類似性検索
数百万~数十億のデータポイントの中から、最も類似したデータをミリ秒単位で見つけ出します。特に生成AIやリアルタイムアプリケーションにおいては、スピードが不可欠です。
3. 非構造化データの扱いに強い
テキスト、画像、音声などの非構造化データをベクトルとして保存・検索可能です。これにより、異なるデータタイプ間の相互検索も容易になります。
例:「この画像に似た商品を探す」といった画像検索や、音声からテキストへの関連データ取得。
4. スケーラビリティ
ベクトルデータベースは分散型で構築されるため、大規模データセットにも対応可能です。データが増加しても、パフォーマンスを維持できます。
5. 機械学習モデルとの統合が容易
生成AIや推薦システムにおいて、事前にトレーニングされた埋め込みモデルを活用して、データベースとスムーズに統合できます。これにより、既存のAIワークフローに簡単に導入できます。
6. 高い精度と信頼性
ベクトル検索では、データの構造や意味を深く理解するため、関連性の高い結果を返します。これにより、検索やAI応答の精度が向上します。
7. マルチモーダルデータの対応
複数のデータ形式(テキスト、画像、音声)を統合して扱えるため、異なる種類のデータを一元的に検索・管理できます。
このように、ベクトルデータベースは従来のデータベースと異なり、AIや機械学習の進化に適応した柔軟性とスピードを提供するため、今後さらに需要が高まる技術です。
埋め込みとは
ベクトルデータベースは、埋め込み(ベクトル埋め込みとも呼ばれる)を保存、検索、取得します。埋め込みとは、テキストや画像、動画といったデータを数値で表現したものです。
これらのベクトルを作成するために、非構造化データはまず「埋め込みプロセス」を経て、機械学習モデルを使用して低次元のベクトルデータに変換されます。
このプロセスの目的は、データ内の意味的な関係性を保持することにあります。
たとえば、Word2VecやBERTのようなモデルを使用すると、類似したアイテムがベクトル空間内で近くに配置されます。
これは、教師あり学習でも教師なし学習でも実現可能です。
これらの埋め込みベクトルの次元数はさまざまで、数十次元のものもあれば数千次元のものもあります。
一般的には、300次元程度のベクトルが多いです。高次元ベクトルデータは情報を多く保持できる一方、効率性の面では低次元ベクトルが優れているため、このバランスを取ることが重要です。
例えば、「オレンジ」「黄色」「バナナ」といった言葉を数値に変換し、それらの関係をマッピングするというコンセプトがあります。
これらを高次元のベクトル空間に配置すれば、色やサイズといった属性に基づいてこれらのアイテムがどのように関係しているかが見えてきます。
もし2つのベクトルがこの空間内で近ければ、それらは何らかの類似性を持っていることを示しています。
これは単語だけでなく、ドキュメント全体、画像、動画といった複雑なデータセットにも同様に適用できます。
ベクトルデータベースはどのように機能する?
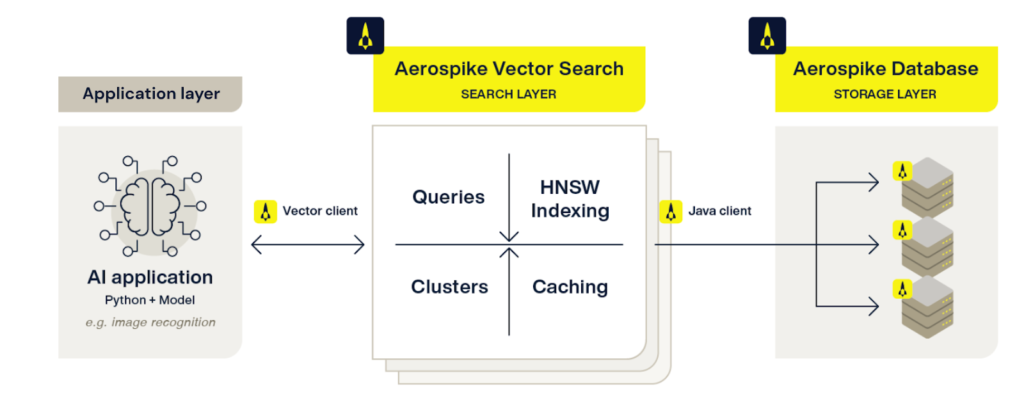
ベクトルデータベースのニーズが分かったところで、機能について見ていきましょう。
プロセスは、非構造化データからベクトル埋め込みを作成することから始まります。
このプロセスの重要な要素には、インデックス作成とメタデータが含まれます。
インデックス作成
非構造化データをベクトル埋め込みに変換することは、最初のステップに過ぎません。
最適化されたインデックス作成は、類似性検索(ベクトル類似性検索とも呼ばれます)を実行するために非常に重要です。
ベクトルデータベースは、ハッシュテーブルやツリー、グラフなどのインデックスを使用してベクトル間の距離を計算し、迅速かつ効率的なデータの取得を可能にしています。
メタデータ
ベクトル埋め込みを保存するだけでなく、ベクトルデータベースはベクトルに関するメタデータ(ベクトルの出所やコンテキストなどの情報)も管理します。
メタデータを効率的にフィルタリングすることで、検索精度が向上し、AIプロセスの効率化も実現します。
多くの企業はメタデータの重要性を認識しているものの、その管理や活用に苦労しています。
ベクトルデータベースとスケーラビリティ
企業がAIアプリケーションをスケールして、より大規模なデータセットや多くのユーザーを処理する際、ベクトルデータベースは高いパフォーマンスと低レイテンシーを提供する必要があります。
スケーラブルなベクトルデータベースは、データ量やクエリ負荷が増加してもAIアプリケーションの効率を維持するために欠かせません。
データ密度と次元性
ベクトルデータベースは、高次元データを扱う際に、データ密度(データがどれだけコンパクトに表現されているか)と次元性(ベクトル内の属性数)のバランスを最適化します。
これにより、複雑なベクトルデータを処理してもパフォーマンスが低下しないようにしています。
リアルタイム更新
リアルタイム更新の管理能力は、詐欺検出やパーソナライズされたレコメンデーションなど、さまざまなAIユースケースにとって重要です。
ベクトルデータベースは、大量のベクトルデータをリアルタイムで処理し、時間に敏感なアプリケーションでの正確さと関連性を維持することが求められます。
複数ユーザーの同時アクセス
スケーラブルなベクトルデータベースは、複数のユーザーが同時にデータベースとやり取りできるよう、高い同時実行性をサポートします。
これにより、ユーザーのトラフィックが多いeコマースプラットフォームなどのリアルタイムアプリケーションでも、パフォーマンスの低下を防ぎます。
ベクトルデータベースのユースケース
ベクトルデータベースの仕組みを理解したところで、ユースケースを見ていきましょう。
これらのユースケースはすべて、ベクトル検索や類似性検索に関係しています。
パーソナライズドレコメンデーションシステムの強化
マッキンゼーの報告によると、71%の顧客がパーソナライズされたサービスややり取りを期待しており、76%がそれが提供されない場合、企業に対して不満を抱くそうです。
サービスをパーソナライズしない企業は、競争の激しい市場で後れを取ってしまいます。
ベクトルデータベースは、レコメンデーションエンジンを支える強力なバックエンドです。
通常、レコメンデーションエンジンはユーザーの閲覧履歴や人口統計情報、さらには製品情報や顧客の過去のデータなど、特定の分野に関連するデータを活用します。
ベクトルデータベースを使用することで、レコメンデーションシステムはリアルタイムでのユーザーデータの流入や、特定分野のデータセットの統合、ペタバイト規模のデータワークロードの処理、そして意味検索を実現できます。
さらに、ベクトルデータベースは、マルチモーダルなレコメンデーションを可能にします。
つまり、ユーザーのやり取りや、写真やテキスト説明といった複数の形式の製品データを組み合わせて、製品をレコメンデーションすることができます。
これは、メディアコンテンツのパーソナライズ、eコマースのレコメンデーション、投資関連のレコメンデーションなどのユースケースに最適です。
リアルタイム分析の最適化
多くの企業がペタバイト規模のデータを扱っていますが、そのデータをいかに効果的に分析するかが鍵となります。
ベクトルデータベースは、IoTセンサーデータのような複雑なデータのリアルタイム分析を可能にし、AIや機械学習アプリケーションの価値を引き出します。
特に、製造業や医療業界では、迅速かつ正確なインサイトが重要です。
チャットボットでのRAGの実装
RAGアーキテクチャを使用することで、企業はベクトルデータベースをAIシステムに統合し、チャットボットでより高速かつ正確な応答を提供できます。
ベクトルデータにアクセスすることで、チャットボットの応答時間が短縮され、AIの「幻覚(ハルシネーション)」も減少し、より一貫性のある関連性の高い回答が可能になります。
適切なベクトルデータベースを選ぶポイント
AIや機械学習のワークロードを最適化するためには、適切なベクトルデータベースの選定が非常に重要です。以下の5つの重要なポイントを参考にデータベース選定を進めるのがおすすめです。
1. パフォーマンスとリアルタイム機能
パフォーマンスと速度の要件を評価しましょう。
必要なデータのスループットや、アプリケーションが許容できるレイテンシのレベルを確認することが大切です。
次のようなベクトルデータベースを探してください:
- 低レイテンシかつ高スループットを提供するもの
- リアルタイムでのインデックス作成や更新が可能なもの
- 大量のベクトルデータを効率的に取り込めるもの
2. スケーラビリティとストレージ
すべてのベクトルデータベースがスケーラビリティを保証しているわけではありません。
将来的な成長を見越した計画が必要です。以下の条件を満たすデータベースを選びましょう。
- データ量やユーザー負荷が増加しても速度と精度を維持できるもの
- システムがスケールするにつれて、コストを管理するためのストレージ最適化がされているもの
3. 効率性
クエリの実行、更新、スケーリングの効率性が高く、コストを最小限に抑えながら速度と精度を最大化できることが重要です。
大規模で高次元のベクトルデータを扱う際には、**総所有コスト(TCO)**を低く抑えることが不可欠です。
4. 開発者に優しく、使いやすい
適切なベクトルデータベースは、既存の技術スタックとシームレスに統合され、さまざまなデータタイプに対応できる開発者向けのツールやAPIを提供する必要があります。
これにより、インフラを大幅に変更することなく、展開やスケーリングが容易になります。
5. 強固なセキュリティとコンプライアンス
生成AI(GenAI)の世界では、サイバーセキュリティやコンプライアンスにおいて多くのリスクがあります。
ガートナーによると、組織の57%がAIによるコード生成で秘密情報が漏洩することを懸念しており、58%が生成AIの出力に偏りがあることを心配しています。
こうしたGenAIに関連する問題は、コンプライアンス違反や法的罰則に数百万ドル規模の損害をもたらす可能性があります。
そのため、企業はHIPAA、GDPR、CCPAなどのフレームワークに準拠しているベクトルデータベースを選ぶ必要があります。
Aerospike Vector Searchを選ぶべき5つの理由
このブログ記事の締めくくりとして、Aerospike Vector Searchを選ぶべき理由を5つ紹介します。
1. AIに最適
Aerospikeは、キーバリューストア、グラフ、ドキュメント、ベクトルデータを取り込み、管理し、活用できるため、リアルタイムAIユースケースに最適な強力なソリューションです。
2. スケールに応じたパフォーマンス
Aerospikeは、HNSWインデックスをデバイス間で並行して構築・組み立てるため、水平スケーリングに対応したデータの取り込みが可能です。
3. 低TCO(総所有コスト)
ハイブリッドメモリアーキテクチャとパーティション化されたインデックス戦略を活用し、リソースを無駄にすることなく、安定した低レイテンシと精度を提供します。
4. 開発者に優しい
Aerospikeは、PythonのサンプルアプリやLangChainの統合を提供しているため、開発者はさまざまなベクトルユースケースに簡単に取り組むことができます。
5. RBAC(ロールベースのアクセス制御)によるセキュリティ
強力なロールベースのアクセス制御を備えたAerospikeは、ユーザーとアクセス権限を最適に管理し、堅牢なセキュリティを提供します。
最も要求の厳しいプロジェクトや野心的なプロジェクトでも、スケールに応じた正確さと速度を実現できるのは、Aerospike以外にありません。
Aerospike Vector Searchにアクセスして、その強力なベクトルデータベースソリューションの革新的な機能をぜひお試しください。
本ブログは2024年10月15日「Vector database 101: What is it, and how does it work?」の翻訳を加筆・修正したものです。