2023年1月にChatGPTの爆発的な人気が始まって以来、AIアプリケーション開発は多くのソフトウェア企業にとって最優先事項となりました。
この結果、新しいデータタイプ(例:ベクトル)、クエリパターン(例:類似性検索)、さらにはAIの精度と関連性を向上させるために異なるデータタイプやクエリパターンを組み合わせる必要があることから、AIデータベースへの関心が高まっています。
現在、AI開発者が利用できるデータベースには多くの選択肢があります。
本記事では、AIの要件に合ったデータベースを見つけるために、複雑なAIデータベースの世界をわかりやすく解説します。
AIデータマネジメント入門 #1: ベクトルデータ
データベースを比較する前に、AIデータベースが求められている機能を理解することが重要です。
まずは、AIデータマネジメントに関する基礎知識から始めましょう。
ベクトルデータとベクトル検索
AIデータマネジメントの中心にあるのは、ベクトルデータとベクトル検索です。
ベクトルは、AIアプリケーションの「通貨」のような存在です。AIの埋め込みモデルによって生成され、テキストの意味、画像の外見、またはeコマースサイトの商品属性など、情報の本質を表しています。
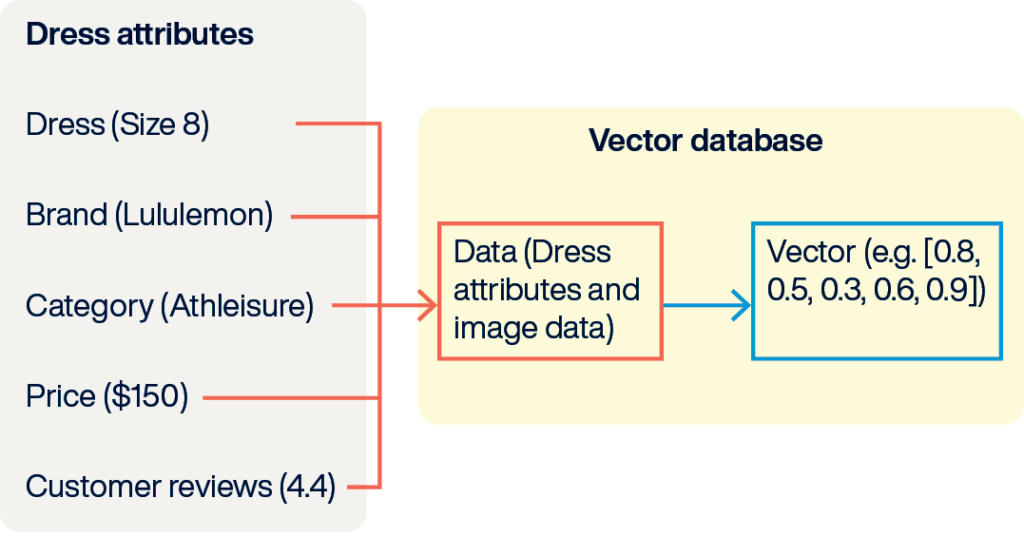
ベクトルは数値の配列であり、その数値はn次元空間における座標を表しています。
次元の数は、そのベクトルを生成した埋め込みモデルに依存します。
たとえば、GPTのような大規模言語モデル(LLM)は数千の次元を持ち、大量の意味情報を記号化できます。
他の特化したモデルでは、特定のデータの特性や測定値に最適化され、少ない次元を持つこともあります。
ベクトル検索では、n次元空間で互いに近接するベクトルを検索します。
近くに位置するベクトルは、意味や外見が類似しているものを表し、類似検索、意味検索、近接検索、最寄り近傍検索などは、ベクトル検索と同義で使われることがあります。
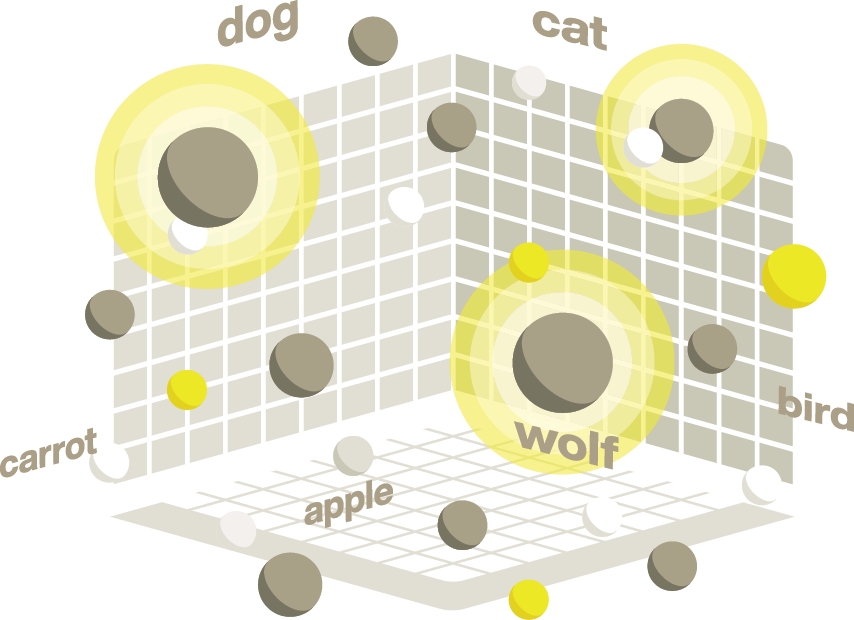
なぜベクトルなのか?
ベクトルとベクトル検索は、大量の非構造化データ(テキスト、画像、ビデオ、オーディオなど)を効率的に検索・分析することを可能にします。
これにより、キーワードやメタデータの手作業での作成という時間のかかるプロセスを排除し、より迅速に多くの情報を活用できるようになります。
AIモデルが、データオブジェクトに対応するベクトルを生成する複雑な作業を行うため、開発者はその部分を心配する必要がありません。
AIデータマネジメント入門 #2: ユースケースとデータアクセスパターン
ベクトル検索は、セルフサービスの営業やカスタマーサポートチャットボット、詐欺検出、レコメンデーションエンジン、広告ターゲティング、ルート計画など、さまざまなセマンティック検索や生成AIアプリケーションの基盤となっています。
AIデータベース管理システム(DBMS)がアプリケーションに最適かどうかを理解するには、ベクトルデータがどのように処理されるかを理解することが役立ちます。
AIアプリケーションでは、以下の3つのパターンがよく見られます。
ベクトル埋め込みの生成
データがモデルに送信され、ベクトルが返されます。このベクトルは、それが表すオブジェクトデータとともに保存されます(または、データが外部に保存されている場合は参照として保存されます)。
異なるモデルタイプが異なるベクトルを生成します(例:LLMや画像分類など)。
ベクトル検索
検索用語がモデルに送られてベクトル化されます。
返されたベクトルは、類似性(最も近い隣人)検索のクエリ入力として使用され、クエリ内のベクトルに意味や外見が類似したデータ項目を見つけます。
ベクトル検索は、他の検索(グラフ検索、SQL検索など)と組み合わせてAIの精度を向上させることができます。
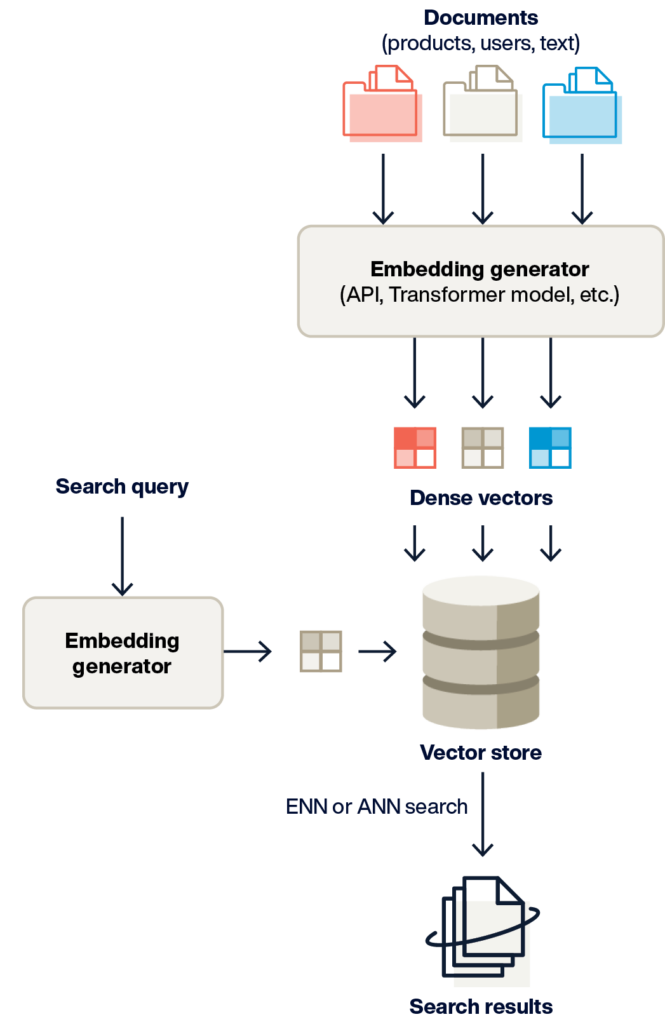
生成AIとRAG(Retrieval-augmented Generation)は、質問への回答、マーケティングコピー、さらにはアプリケーションのソースコードなど、新しいコンテンツをAIが生成する技術です。
この仕組みは、先に説明したベクトル検索パターンと似ていますが、RAGの場合は、クエリベクトルがGenAIモデルに送信される際に、追加のステップとして関連するコンテンツを取得するプロセスが含まれます。
この取得されたコンテンツに基づき、モデルは製品マニュアルやユーザーデータといった特定の情報を元に、生成された回答を提供することが可能になります。
さまざまな検索技術を用いて、この補完的な情報を取得することができます。

AIデータベースの役割
ベクトルデータとその処理方法を理解したところで、AIアプリケーションスタックにおけるAIデータベースの役割を見てみましょう。
データベース管理システム(DBMS)は、AIアプリケーションスタックにおいて非常に重要な役割を果たします。基本的なレベルでは、AIアプリケーションデータベースは次の機能を提供します。
- ベクトルデータの保存
- ベクトルデータのインデックスを管理し、検索速度を向上
- ベクトル検索の実行
- データのセキュリティとアクセス制御
AIデータベースの違いは、スケール、パフォーマンス、拡張性、予算など、さまざまなAIプロジェクトの要件にどのように対応できるかにあります。
たとえば、社内のAI概念実証プロジェクトに適したデータベース(多くのデータベースがこれに対応)は、数千人のユーザーが何十億ものベクトルを同時に検索するような、対市場向けのAIアプリケーションには適していない場合があります。
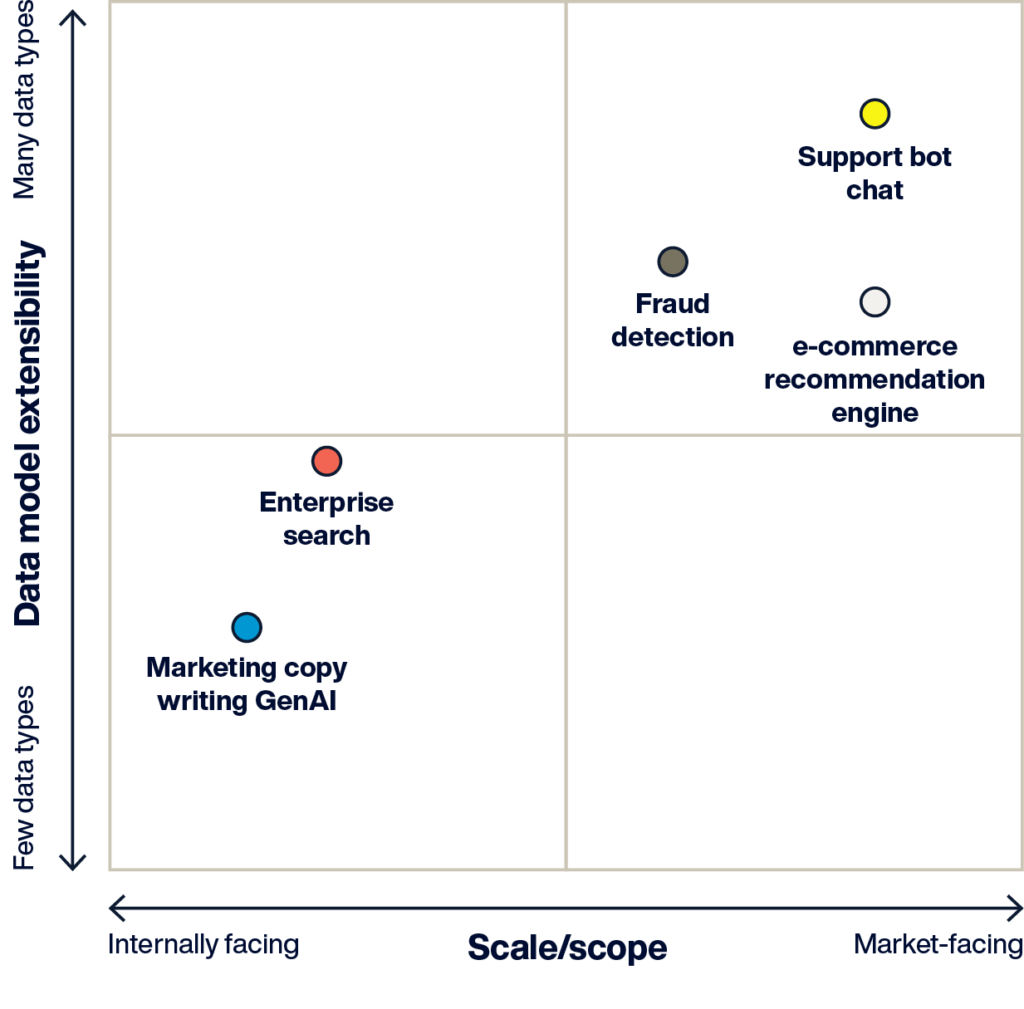
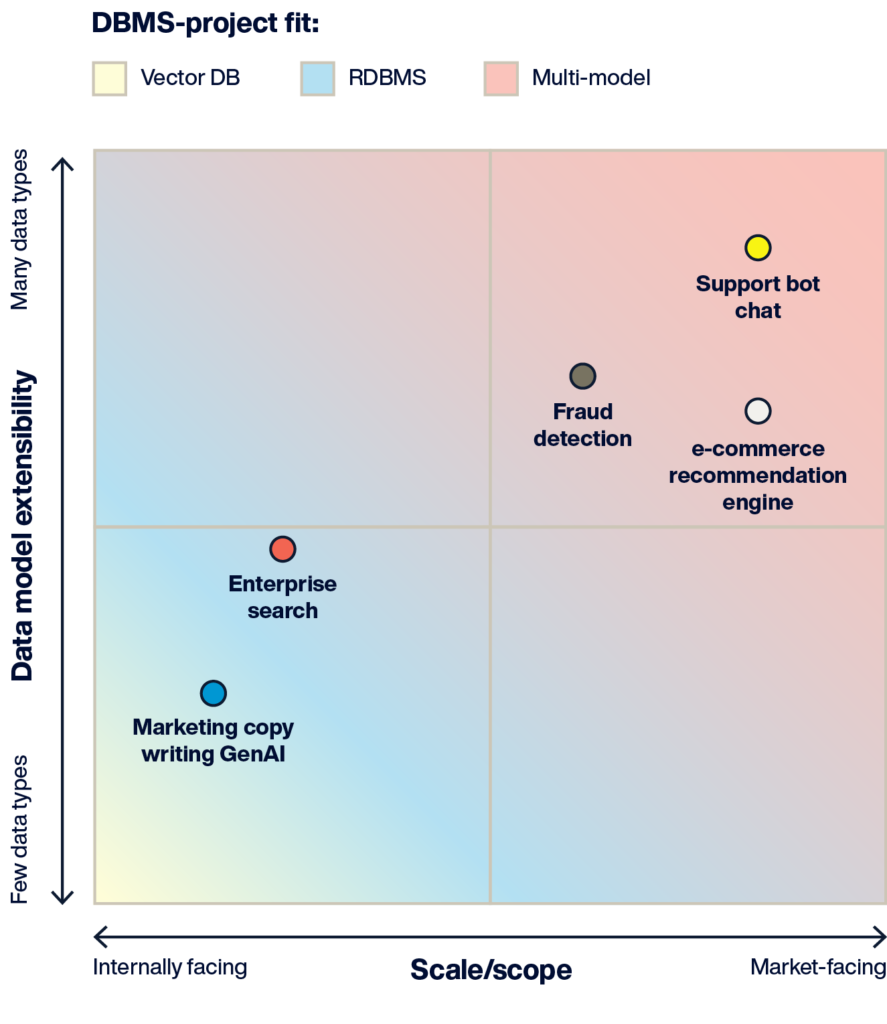
上記の図は、AIアプリケーションのデータ管理要件を理解するためのフレームワークを提供しています。
- 内部向けアプリケーション: マーケティングチームが使用するコピー生成ツールのように、同時に1~100人程度のユーザーが利用します。ダウンタイムやパフォーマンスの低下は許容範囲内(業務に支障が出ることはあっても、顧客やブランドには影響しない)。
- 市場向けアプリケーション: eコマースのレコメンデーションエンジンのように、同時に100~1000人のユーザーが利用します。顧客体験を良好に保つため、24時間365日の高速パフォーマンスが求められます。
- シンプルなデータモデル: ベクトルデータのみを使った小規模なデータで、単一の検索(例: ベクトル類似検索)にアクセスする企業向けドキュメント検索ポータルなど。
- 複雑なデータモデル: テラバイト規模の多様なデータとインデックスを管理し、ベクトル検索やグラフ検索、フィルタ検索を組み合わせて不正行為を検出するシステムなど。
AIデータベースを評価するための比較基準
プロジェクト要件に最適なAIデータベースを選択する際、以下の比較ポイントを使用して技術面とビジネス適合性を評価すると役立ちます。
- 拡張性: DBMSは、ベクトル、JSON、グラフ、SQLなど、さまざまなデータ形式をサポートできるか?
- スループット: 多数の同時ユーザーリクエストを高速かつコスト効率よく処理できるか?
- データボリューム: 大量(テラバイト単位)のデータをコスト効率よく保存、インデックス化、更新、検索できるか?データを更新しながらクエリを実行できるか?
- プロダクション準備度: データを保護し、ノンストップのパフォーマンスを確保するための機能があるか?
これらの4つの評価基準により、あらゆるAIアプリケーション開発プロジェクトの要件に応じてAIデータベースの選択肢を比較するためのシンプルで客観的なフレームワークが形成されます。
AIデータベースの選択
このフレームワークを使用して、次の3つの代表的なAIデータベースカテゴリの比較を見てみましょう。
- ベクトルデータベース(例: Pinecone)
- リレーショナルデータベース(例: PostgreSQL + PgVector)
- マルチモデルデータベース(例: Aerospike)
ベクトル検索
概要
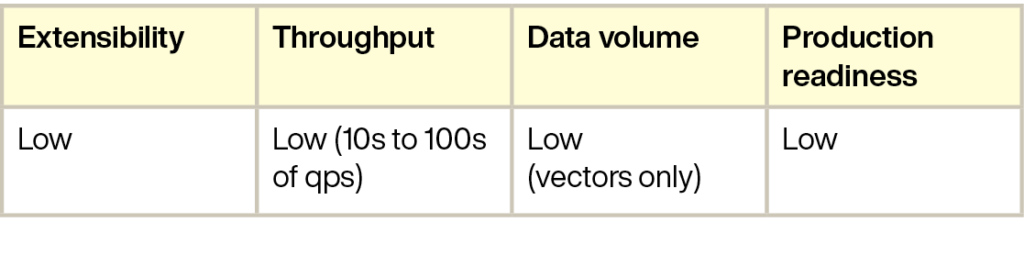
ベクトルデータベースは、ベクトルデータの管理と検索に特化しています。有名な例としてPineconeがあります。
Pineconeは、人気のLLM(大規模言語モデル)や他のAIモデルと連携できる、フルマネージドのクラウドベースのベクトルデータベースです。
主にベクトル埋め込みを生成し、それらのベクトルに対して類似性検索を実行します。
Pineconeはベクトルレコードのみを保存し、フィルタリング用に最大40KBのユーザー定義メタデータを含めることができます。
しかし、ベクトルのみを扱うため、元データの管理(ベクトルが表すソースデータの管理)や、リレーショナルデータ、グラフデータ、全文検索など他の検索は別のシステムで行う必要があります。
この分離により、拡張性が制限され、複雑な作業には他のデータベースとの統合が必要となります。
パフォーマンス
Pineconeは異なるパフォーマンスオプションを提供しています。
Pineconeには、サーバーレスとポッドベースの2つのパフォーマンスオプションがあります。
ポッドベースの場合、パフォーマンスの制御がより柔軟になります。
ポッドは、ポッドの種類やデータベースのサイズに応じて、1秒あたり10~50のクエリを実行できます。
バッチアップサートには100個以下のベクトルを含めるべきです。
クラウドサービスであるため、ネットワークの遅延がパフォーマンスに影響を与え、クエリ結果やその他のデータベースリクエストの処理に追加の遅れが発生することがあります。
Pineconeのようなベクトルデータベースは新しく、プロダクションレベルの機能に関してはまだ成熟していません。
Pineconeには、データベースのバックアップやリストア、データの整合性、データベースの監視や可観測性といった機能が欠けており、他のデータベースと比べてアクセス制御の面でも遅れをとっています。
結論
Pineconeのようなベクトルデータベース(WeaviateやQdrantといったオープンソースの代替も含む)は、ベクトル検索に特化しており、概念実証や社内向けのセマンティック検索アプリケーションのようなシンプルなプロジェクトに適しています。
しかし、ベクトル検索以外の用途に拡張する場合は、複数のデータベースが必要となり、開発が複雑化し、インフラコストが増加し、パフォーマンスが低下します。
さらに、バックアップ、セキュリティ、可観測性といった運用品質の機能が未成熟または欠けているため、管理コストが増加し、データの可用性が危険にさらされることもあります。
より大規模なプロダクション向けのAIアプリケーションには、より堅牢なマルチモデルデータベースが適しているかもしれません。
リレーショナルデータベース

概要
リレーショナル(SQL)データベースは最も広く使用されているDBMSで、多くのデータベースはベクトルデータのインデックス化と検索に対応する機能を追加しています。
PgVector拡張機能は、人気の高いオープンソースリレーショナルデータベースであるPostgreSQLにこの機能を提供します。
RDBMSでベクトル検索をサポートするメリットは、ベクトルを他のリレーショナルデータと共に保存し、SQLを使って検索できる点です。
これにより、SQLの高度なフィルタリング、ソート、処理機能を活用し、クエリ結果に対する制御が強化されます。
すべてのデータを1つのデータベースに統合することで、開発がシンプルになり、既存のSQLデータベースのスキルやツールを活用し、インフラコストを削減できます。
さらに、ACIDデータ整合性、徹底したデータベースセキュリティ、パフォーマンス監視、バックアップ/リストアといった成熟したプロダクションデプロイメント機能の恩恵も受けられます。
パフォーマンス
クエリとCRUD操作のパフォーマンスは、ベクトルデータベースよりも高速で、ある程度の規模までは実証されています。
ただし、リレーショナルデータベースは大規模データセット(>100万行)や多くの同時ユーザーを処理するためのスケーリングが得意ではありません。
SQL結合や過剰なインデックス作成は、リレーショナルデータベースのパフォーマンスとスループットを阻害し、広告ターゲティング、エクスペリエンスのパーソナライズ、レコメンデーションエンジンなどのリアルタイムベクトル検索を不可能にします。
結論
リレーショナルSQLデータベースは、ベクトルインデックス化と検索のサポートが進んでいます。
SQL RDBMSを頻繁に使用しており、利用しているRDBMSがベクトル検索に対応している場合、小規模から中規模のAIプロジェクトには適した選択肢です。
ただし、より高いパフォーマンスやスケール(データ量やスループット)、クエリの複雑さが必要な場合、市場向けのAIシステムでは、データエンジニアリングの課題やパフォーマンスの低下、高額なインフラコストが課題となります。
マルチモデルデータベース
概要
マルチモデルデータベースは、さまざまなデータモデルをサポートできます。
例えば、Aerospikeは幅広いデータタイプをサポートし、ベクトル、グラフ、時系列、JSON、地理空間データなどを扱うことができます。
マルチモデルデータベースは、AIデータ処理のあらゆる要件に対応できる最大の拡張性を提供します。
マルチモデルデータベースは、AI検索を制御するための多くの手段を提供します。
RAGアーキテクチャでクエリに関連するデータを取得したり、返されたベクトル検索結果を強化したりすることができます。
これにより、ユーザーにより興味深い洞察を提供し、AIモデルにより関連性の高いデータを供給することで、より正確なAI応答を生成できます。
また、単一のデータベースアーキテクチャによって開発をシンプルにするだけでなく、Aerospikeはセキュリティ、監視、SQLツールの互換性、バックアップ/リストアなどの成熟したプロダクションデプロイメント機能も提供します。
パフォーマンス
Aerospikeの特許取得済みのハイブリッドメモリアーキテクチャ、並列処理、独立してスケーラブルなコンピュートおよびキャッシュレイヤーにより、Aerospikeは新しいベクトルデータを同時に取り込みながら、1秒あたり数千のクエリを処理できます。
これにより、Aerospikeは大規模なデータ(数兆のベクトル、数百テラバイトのデータ)や多くの同時ユーザーを処理し、リアルタイムAIのユースケース(詐欺検出、広告ターゲティングなど)に適しています。
また、Aerospikeは他の代替手段と比較して80%少ないインフラでワークロードを処理できることが証明されています。
結論
AerospikeのようなマルチモデルAIデータベースは、あらゆるユースケースに対応できる拡張性を提供します。大規模なベクトル処理を高スループットでサポートし、リアルタイムユースケースにも対応しながら、インフラコストを80%削減します。
DBMS
概要
上記の図は、推奨されるAIプロジェクトタイプとDBMSの適合性を示しています。
ベクトルデータベース:このニッチなデータベースは、概念実証(PoC)のAIプロジェクトに適しています。しかし、拡張性の欠如や本番環境での未熟さが、大規模な使用において課題を引き起こします。拡張性や大量のデータを扱うためには、複数のDBMSアーキテクチャが必要です。
リレーショナルデータベース+ベクトル:これにより、多くのAIプロジェクトで複数データベースアーキテクチャの必要性が排除されますが、リアルタイムAI、広範なユーザーベース、または大量データの処理にスケーリングすることは課題となります。
マルチモデル:最も幅広いデータモデルのサポートと拡張性、高性能なDBMSアーキテクチャを備えており、リアルタイムパフォーマンス、大規模な同時接続ユーザーベース、またはAIの精度要件があるAIアプリケーションに最適です。
このガイドが、AIプロジェクトタイプに合ったAIデータベースの能力を理解するのに役立ったことを願っています。
本ブログは2024年9月16日「Navigating the AI database landscape」の翻訳です。